
Gobernando los metadatos de ingesta con más metadatos — y sabiendo cuál metadato es cuál.
Una llave de un grifo no es confiable porque alguien la instaló bien. Es confiable porque existe un código de construcción que especifica cómo debe instalarse. Hay un inspector que verifica la instalación. Hay un sello de certificación en la conexión. Hay un registro —en un archivero en algún lado— de quién aprobó el permiso y cuándo. Capas de gobierno que verifican otras capas de gobierno. Nadie confía en una sola capa. Ni en plomería. Ni en metadatos.
El post anterior dijimos que el YAML se valida contra un schema antes de correr. Hoy abrimos esa caja.
En un sistema dirigido por metadatos, el metadato mismo es un artefacto que necesita gobierno. Y ese gobierno lo da… más metadato. Son metadatos hasta el fondo —pero no todos los metadatos cumplen el mismo rol, y confundir uno con otro es como estos modelos dejan de sentirse limpios y empiezan a sentirse como un sistema de archivado que alguien forzó sobre una pizarra.
El YAML del Post 1, por elegante que sea, no vale nada sin las capas que lo rodean.
El marco: origen, no uso
«Es mejor pensar en estas categorías en relación a de dónde se origina el metadato, en lugar de cómo se usa.» — DMBOK v2, Cap. 12 (Metadata Management), §1.3.2 Types of Metadata, p. 422
El error fácil al modelar metadatos es agruparlos por uso: «esto me ayuda a clasificar», «esto me ayuda a validar», «esto me ayuda a auditar». Cada agrupamiento es tentador porque refleja cómo se siente el metadato en el momento que lo consumís. Pero los agrupamientos se cruzan entre sí. Un solo tag lo usan las herramientas de gobierno, los escáneres de seguridad y la documentación. Una sola fila de log alimenta dashboards de ops, reportes de calidad y diagramas de linaje. El uso es una telaraña, no una jerarquía.
El origen sí es una jerarquía. Hacé otra pregunta: ¿dónde nació este metadato?
En nuestro sistema, dos orígenes importan:
- Metadato de configuración — nace del contrato declarativo. Vive en Git. Lo editan humanos. Se cambia vía PR. Gobierna el qué y cómo ingerís. Su cadencia es la cadencia de las decisiones de ingeniería: nueva entidad, nueva fuente, nueva regla de clasificación.
- Metadato operacional — nace de la ejecución. Se genera como efecto colateral. Nunca se edita a mano. Registra qué pasó cuando ingeriste. Su cadencia es la cadencia del runtime: cada corrida, cada entidad, cada evento de cuarentena.
Se parecen desde afuera —ambos son «datos estructurados sobre datos». Pero responden a amos distintos. El metadato de configuración responde al code review. El operacional responde al motor que lo produjo.
Este post es sobre el primer origen. El stack de configuración tiene cuatro capas, cada una con un rol distinto. El metadato operacional es otro bicho con otra historia, y llegaremos a él en el Post 4.
Las cuatro capas
El modelo, en una tabla:
| Capa | Qué es | Dónde vive | Ejemplo |
|---|---|---|---|
| L1 YAML | El contrato declarativo mismo | Git, config/ | Sales_Salesforce.yml |
| L2 Tags | Metadato de clasificación embebido dentro del YAML | Dentro del archivo YAML | security.sensitivity: "PII" |
| L3 Convención de nombrado | Metadato que gobierna al YAML desde afuera | Filename + linter de CI | {Domain}_{Source}.yml |
| L4 Yamale | El metamodelo que valida la estructura del YAML | ingestion_schema.yaml | source_type: enum("relational", "file") |
El orden es intencional: de adentro hacia afuera desde el YAML.
- L1 es el artefacto. La cosa a la que le hacer Commit.
- L2 vive dentro del artefacto. Los tags están embebidos en el YAML, viajando con cada entidad.
- L3 gobierna al artefacto desde afuera. El nombre del archivo es metadato que el YAML no puede contener —es la identidad del archivo, no su contenido.
- L4 es el metamodelo. Metadato sobre la estructura del metadato. Un nivel más abstracto que cualquier cosa debajo.
Una observación útil: la estabilidad aumenta a medida que te movés hacia afuera. El contenido del YAML cambia cada vez que agregás una entidad. Los tags cambian cuando gobierno reclasifica. La convención de nombrado casi nunca cambia. El schema de Yamale cambia solo cuando el estándar evoluciona —trimestralmente, no semanalmente. Esto no es casual. Las capas externas son los cimientos; son las partes que no querés renegociar seguido. Las capas internas son las partes que tienen que evolucionar con el negocio.
Una segunda observación, menos obvia: las capas no se apilan en dirección de «importancia». Se apilan en dirección de «abstracción». L1 no es más importante que L4; es más concreta. L4 no es más importante que L1; es más abstracta. Cada capa hace un trabajo que las otras no pueden. Sacá cualquiera y el sistema se degrada de una manera específica y predecible:
- Sacá L2 y tenés que catalogar después del hecho.
- Sacá L3 y la identidad se desvía del contenido.
- Sacá L4 y los typos estructurales se cuelan del review al runtime.
- Sacá L1 y la ingesta colapsa de vuelta a un pipeline por fuente —el problema con el que abrió la serie.
Recorramos las cuatro capas con el problema que resuelve cada una.
Capa 1 — El YAML como contrato
El Post 1 cubrió L1 en profundidad. Lo que no respondió es qué gobierna al contrato mismo —y cada una de las tres capas siguientes resuelve una pregunta distinta que L1 sola no puede:
- ¿Cómo clasificamos el contenido (PII, propiedad, sensibilidad)? → L2 Tags
- ¿Cómo mantenemos la identidad del YAML consistente con su contenido? → L3 Convención de nombrado
- ¿Cómo nos aseguramos de que el YAML esté bien formado antes de que corra? → L4 Yamale (un validador de schemas de YAML open-source —más sobre él abajo)
Capa 2 — Tags: metadato en tránsito
Los tags viajan dentro del YAML, pero su destino no es el motor de ingesta —es el sistema de gobierno externo.
config:
tags:
security.sensitivity: "confidential"
governance.data_owner: "Sales"
entities:
- name: Opportunities
tags:
security.sensitivity: "restricted" # sobrescribe el tag global
security.classification: "PII"
El patrón es herencia con override. El bloque config.tags define defaults que aplican a cada entidad del YAML. Una entidad individual puede sobrescribir un tag específico cuando lo necesita —Opportunities es PII aunque el resto de la fuente sea apenas confidencial. El caso común es barato (una declaración cubre todo); el caso especial es explícito (una línea donde importa).
Por qué importa: la clasificación no es un paso que pasa después. Nace con la configuración. Para cuando una entidad aterriza en Bronze, ya carga su etiqueta de gobierno. No hay fase de «la taggeamos después de perfilarla» —y cualquiera que haya trabajado en una empresa grande sabe que esa fase es donde va a morir la clasificación.
La metáfora: una carta dentro de un sobre. El YAML es el sobre —editado en Git, copiado al Lakehouse en el despliegue como artefacto de solo lectura, abierto ahí por el motor en runtime. Los tags son la carta adentro: una vez que el motor aterriza el dato, los tags viajan junto con él al escáner de seguridad, al dashboard de gobierno, al reporte de compliance. El sobre se detiene en el Lakehouse; la carta sigue viajando.
La tensión honesta: decidir qué tags son globales y cuáles son por entidad es una conversación con gobierno, no una decisión de código. Lleva más tiempo del que los equipos de ingeniería esperan. Una vez que esa conversación converge, el patrón de herencia protege el resultado —pero saltarse la conversación produce o un YAML donde todo está taggeado «confidential» (inútil) o un YAML donde cada entidad redeclara cada tag (frágil).
Otro viajero: template version. No toda pieza de metadato dentro del YAML es un tag. template_version: "1.0" es un campo de versionado —también embebido en L1, también metadato en tránsito, pero su destino es el motor, no un sistema de gobierno. Cuando el contrato necesita crecer —una sección nueva, un campo requerido nuevo— publicás "2.0" y el motor aprende a procesar ambos. Los YAMLs existentes no se rompen; los nuevos adoptan la versión actual. Versionado semántico para tus contratos de metadatos: la misma disciplina que permite a las APIs evolucionar sin romper clientes permite a tu contrato de ingesta evolucionar sin romper los YAMLs ya en producción.
Capa 3 — El nombre del archivo como contrato de gobierno
El Post 1 introdujo filename-as-metadata como principio de diseño. Acá se gana su lugar como capa de gobierno.
El mecanismo: Sales_Salesforce.yml no es un nombre —es un contrato. Domain=Sales, source=Salesforce. El esquema del Lakehouse se deriva del filename, nunca se configura a mano. El YAML no duplica esos atributos. No puede contradecirlos. La identidad del archivo y el contenido del archivo se reconcilian por construcción, no por revisión.
Por qué esto es gobierno: elimina una categoría entera de inconsistencia —esa donde el YAML dice una cosa y el filename dice otra y solo te enterás cuando una consulta downstream devuelve cero filas. Eliminar una clase entera de bugs haciéndolos irrepresentables vale más que cualquier cantidad de validación que los atrape después del hecho.
Patrones observados a través de proyectos:
| Patrón | Ejemplo | Cuándo encaja |
|---|---|---|
{Domain}_{Source} | Sales_Salesforce.yml | Una implementación por fuente (el caso común) |
{Source}_{Domain} | ERP_Finance.yml | Organizaciones donde la fuente es el eje de navegación principal |
{Source}_{Country}_{Domain} | SAP_MX_Accounting.yml | Multi-país, misma fuente, implementaciones regionales |
El invariante: dominio y fuente son siempre explícitos. El país es opcional y específico del proyecto. El nombre del esquema siempre se deriva, nunca se configura. Esa última regla es la que convierte una convención en un contrato —si no podés sobrescribir el nombre del esquema en el YAML, el filename gana por construcción.
Capa 4 — Yamale: el unit test de tu metadato
El Post 1 dijo que el YAML se valida contra un schema. Así es cómo.
El problema que resuelve: sin validación, un typo —source_tipe: relational en lugar de source_type— pasa silencioso y falla en runtime, en producción, después de que el PR mergeó y todos se movieron a otra cosa. El YAML era «válido» según la gramática de YAML. Simplemente no significaba lo que el motor esperaba que significara.
Yamale en una frase: un schema declarativo que define la estructura válida de tu YAML —tipos, enums, campos requeridos, campos opcionales, formas anidadas. Escrito en YAML mismo, porque el metamodelo del metadato quiere parecerse al metadato.
config:
template_version: str(required=True)
source_type: enum("relational", "file", required=True)
source_system: map(required=True)
tags: map(required=False)
entities: list(required=True)
entities.*.name: str(required=True)
entities.*.query: str(required=False)
entities.*.path: str(required=False)
entities.*.tags: map(required=False)
Dónde corre: en el flujo GitOps, pre-despliegue. Si Yamale falla, el YAML nunca llega al Lakehouse. Es una puerta, no un log. El feedback cae en el PR, mientras el autor todavía está en contexto, no en producción semanas después cuando ya se olvidó del cambio por completo.
Yamale es el unit test de tu metadato. Si el YAML es el contrato entre configuración y ejecución, Yamale es el linter del contrato.
La limitación honesta: Yamale valida estructura, no semántica condicional. Puede decir «query tiene que ser un string». No puede decir «si source_type es relational, entonces query es requerido, pero si source_type es file, entonces path es requerido». Las reglas con un if no pueden vivir en un schema —al menos no sin convertir el schema en un segundo lenguaje de programación.
La solución: validación en dos capas. Yamale valida estructura pre-despliegue. El notebook valida reglas condicionales en runtime. Cada capa hace lo que sabe hacer, y ninguna finge ser la otra. El trade-off es consciente: Yamale se mantiene simple y declarativo; las reglas condicionales viven en el motor donde los if son baratos.
Una pregunta que vale hacerse: ¿dónde ponés el corte entre validación declarativa e imperativa? No hay respuesta universal —pero hay un principio: si la regla se puede expresar sin lógica, va al schema. Si necesita un if, va al código. Esa línea es la que evita que los schemas se pudran en DSLs ad-hoc.
Las cuatro capas en una imagen
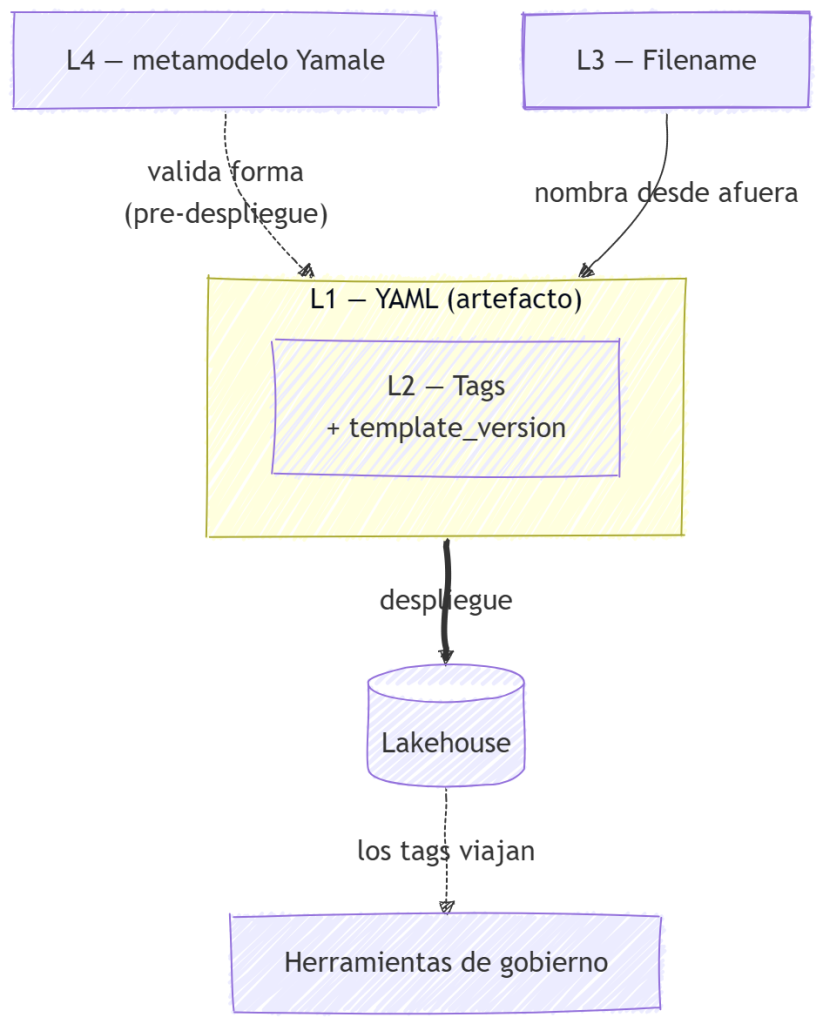
Cuatro capas, cuatro roles. L2 viaja dentro de L1 como payload de clasificación. L3 nombra a L1 desde afuera. L4 valida la forma de L1 desde arriba. Cada una hace algo que las otras tres no pueden.
Cada capa se origina en un lugar distinto. Eso es lo que evita que sus roles colapsen en uno.
Confianza construida capa por capa
Ninguna de estas capas estuvo planeada el día uno. Cada una emergió de un problema real. El typo que tumbó una carga nocturna. El YAML que pasó la review pero tenía el filename renombrado en la dirección equivocada, y el schema que se desvió silencioso de su fuente. El tag que existía solo en una planilla y se olvidó cuando la entidad fue a producción. Cada moretón fue un argumento por una capa.
Volviendo a la metáfora del Post 1: Bronze debería ser aburrido. Ahora sabés lo que hace falta para que sea aburrido de forma confiable. La llave no es solo funcional —podés demostrar por qué funciona, quién la aprobó, y qué pasa si algo cambia. Eso no es burocracia. Eso es cómo se ve cuando la confianza es una propiedad de ingeniería en lugar de una propiedad social.
«Metadatos hasta el fondo» suena a chiste filosófico. En producción, es una estrategia de supervivencia.
Qué viene
Post 3 — Battle Scars: El YAML se veía perfecto en el PR. Después Spark 3.x rechazó fechas de 1753, un pipeline crasheó y dejó un lock que bloqueó todo por seis horas, y el YAML en Git resultó no ser el que estaba corriendo en el Lakehouse. Lecciones operacionales y cicatrices de producción.
Post 4 — Living Metadata: Todas esas tablas de control generando metadato con cada corrida. Pero si nadie las lee, es metadato muerto. Cómo los logs se vuelven reportes y los reportes se vuelven decisiones —y por qué esa es la diferencia entre un catálogo que vive y uno que se pudre.
← Anterior: Bronze debería ser aburrido | → Siguiente: El Calendarizador
Este es el segundo post de la serie «Ingesta dirigida por metadatos en YAML». Los patrones descritos evolucionaron a través de varias implementaciones de Lakehouse empresariales y son agnósticos a la plataforma, aunque nuestra plataforma de referencia es Microsoft Fabric.
Deja una respuesta