
En el artículo “SQL SERVER: ¿Qué son las estadísticas en SQL Server y para qué sirven?” escribí acerca de estos objetos y un amigo costarricense me pidió que compartiera algunos de los scripts que uso, para manejar estos objetos.
Como encontrar estadísticas creadas automáticamente
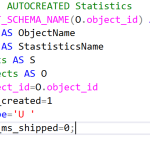
La siguiente consulta puede ayudarle a encontrar dichas estadísticas:
---- List of AUTOCREATED Statistics SELECT OBJECT_SCHEMA_NAME(O.object_id) AS SchemaName , O.name AS ObjectName , S.name AS StastisticsName FROM sys.stats AS S JOIN sys.objects AS O ON S.object_id=O.object_id WHERE S.auto_created=1 AND O.type='U ' AND O.is_ms_shipped=0;
La consulta hace uso de las vistas de catálogo de sistema sys.stats y sys.objects que están disponibles desde versiones de SQL 2005, y se filtran con tres condiciones: que sean auto creadas, que sean sobre objetos tipo tabla de usuario (para no meternos con catálogos de sistema) y finalmente que NO sean objetos creados por componentes de SQL Server. Si quiere filtrarse los datos por tabla, es tan fácil como agregar una condición más al WHERE.
Como encontrar la fecha de actualización de las estadísticas
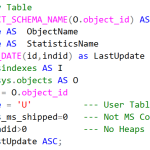
Para esta pregunta hay dos alternativas, la más simple retorna una fila por cada estadística, y emplea la función STATS_DATE. Implícitamente, trabaja con la idea que el SQL mantiene las estadísticas por tabla, cuando en realidad lo hace por columna, pero es una buena aproximación
-- Simple by Table SELECT OBJECT_SCHEMA_NAME(O.object_id) AS SchemaName , O.name AS ObjectName , I.name AS StatisticsName , STATS_DATE(id,indid) as LastUpdate FROM sys.sysindexes AS I INNER JOIN sys.objects AS O ON I.id = O.object_id WHERE O.type = 'U' --- User Table AND O.is_ms_shipped=0 --- Not MS Component AND I.indid>0 --- No Heaps ORDER BY LastUpdate ASC;
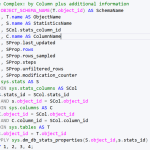
Si se quiere una consulta más específica, que vea el detalle por columnas, entonces la siguiente sentencia puede ayudar a ver las fechas y otros detalles que pueden ser interesantes de analizar y que la función dm_db_stats_properties provee:
--- More Complex: by Column plus additional information SELECT OBJECT_SCHEMA_NAME(T.object_id) AS SchemaName , T.name AS ObjectName , S.name AS StatisticsName , SCol.stats_column_id , C.name AS ColumnName , SProp.last_updated , SProp.rows , SProp.rows_sampled , SProp.steps , SProp.unfiltered_rows , SProp.modification_counter FROM sys.stats AS S INNER JOIN sys.stats_columns AS SCol ON S.stats_id = SCol.stats_id AND s.object_id = SCol.object_id INNER JOIN sys.columns AS C ON C.object_id = SCol.object_id AND C.column_id = SCol.column_id INNER JOIN sys.tables AS T ON c.object_id = T.object_id OUTER APPLY sys.dm_db_stats_properties(S.object_id,s.stats_id) AS SProp ORDER BY 1, 2, 3, 4;
Cómo listar todas las columnas que participan en las estadísticas
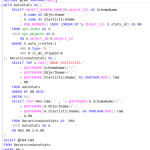
En ocasiones queremos entender cuáles son las columnas que tienen estadísticas, ya que esto nos da una idea general de cuando se están empleando las consultas como predicados (en WHERE o como condiciones de JOIN) y puede eventualmente dar una idea si hay estadísticas redundantes o si más bien podría considerarse un índice. La consulta es:
SELECT object_name, StatisticsName, auto_created, user_created , [1], [2], [3], [4], [5], [6], [7], [8], [9], [10] , [11], [12], [13], [14], [15], [16], [17], [18], [19], [20] , [21], [22], [23], [24], [25], [26], [27], [28], [29], [30] , [31], [32] FROM ( SELECT OBJECT_NAME(S.object_id) AS object_name , SCol.stats_column_id , C.name AS ColumnName , S.name AS StatisticsName , S.auto_created, S.user_created FROM sys.stats AS S JOIN sys.stats_columns AS SCol ON s.object_id=SCol.object_id and s.stats_id = SCol.stats_id INNER JOIN sys.columns AS C ON C.object_id = SCol.object_id AND C.column_id = SCol.column_id WHERE s.object_id not in (select object_id from sys.objects where is_ms_shipped=1) ) AS Source PIVOT (MAX(ColumnName) FOR stats_column_id IN ([1], [2], [3], [4], [5], [6], [7], [8], [9], [10] , [11], [12], [13], [14], [15], [16], [17], [18], [19], [20] , [21], [22], [23], [24], [25], [26], [27], [28], [29], [30] , [31], [32])) AS Pvt ORDER BY StatisticsName;
Cómo borrar estadísticas creadas automáticamente
Antes de que copies y pegues el código de borrado, vale la pena señalar, que borrar estadísticas suele ser una mala práctica, que no mejora el desempeño y que con frecuencia lo empeora. Mi recomendación casi siempre suele ser que NO borres las estadísticas. Sin embargo, entiendo que hay algunas ocasiones (por más extrañas que sean) que puede ser necesario. Creo que en mi práctica profesional solo en dos ocasiones, borre estadísticas de forma masivamente. En la primera ocasión, un desarrollador quería copiar un esquema de base de datos entre dos compañías, y algunas tablas tipo catálogo (ya que las empresas eran competencia, pero financiaron el proyecto de forma conjunta) y quería asegurarse que no quedara nada de información de pruebas en el ambiente de producción. Y en la segunda un cliente que estaba haciendo perfilamiento de datos, y termino con estadísticas en cada columna de la base de datos y estaba preocupado por el impacto en el servidor. Como era un cliente porfiado, no pude convencerlo que era innecesario el borrado y aunque no muy convencido, igualmente procedí con el borrado.
---- Drop all Auto-Create Statistics
DECLARE @Cmd VARCHAR(MAX);
WITH AutoStats AS (
SELECT OBJECT_SCHEMA_NAME(O.object_id) AS SchemaName
, O.name AS ObjectName
, S.name AS StastisticsName
, ROW_NUMBER() OVER (ORDER BY S.object_id, S.stats_id) AS RN
FROM sys.stats AS S
JOIN sys.objects AS O
ON S.object_id=O.object_id
WHERE S.auto_created=1
AND O.type='U '
AND O.is_ms_shipped=0
), RecursiveAutoStats AS (
SELECT TOP 1 CAST('DROP STATISTICS '
+ QUOTENAME(SchemaName)+'.'
+ QUOTENAME(ObjectName)+'.'
+ QUOTENAME(StastisticsName) AS VARCHAR(MAX)) Cmd
, RN
FROM AutoStats
ORDER BY RN DESC
UNION ALL
SELECT CAST(RAS.Cmd+ ' , '+ QUOTENAME(A.SchemaName)+'.'
+ QUOTENAME(A.ObjectName)+'.'
+ QUOTENAME(A.StastisticsName) AS VARCHAR(MAX)) Cmd
, A.RN
FROM RecursiveAutoStats AS RAS
JOIN AutoStats AS A
ON RAS.RN-1=A.RN
)
SELECT @Cmd=Cmd
FROM RecursiveAutoStats
WHERE RN=1
EXEC (@Cmd)
El código se basa en la consulta anterior que usa como base, pero usa una consulta recursiva para concatenar todas las estadísticas, empezando por la ultima (por eso TOP 1/ORDER BY DESC), para que al final solo dejarse la primera fila que es la concatenación de todas las anteriores. Finalmente, el EXEC ejecuta dinámicamente la consulta.
Conclusión
Espero que las consultas anteriores sean herramientas útiles en tu caja de herramientas de SQL Server. Si te interese puedes leer más sobre estadísticas en: “SQL SERVER: Mejores Prácticas: Estadísticas” o si quiere ver detalles de lo que contienen: “SQL SERVER: Como leer DBCC SHOW STATISTICS”. Como siempre puedes bajar el código de GITHub en StatisticsQueries.sql:
Deja una respuesta