
Este artículo trata de sobre una técnica que diseñe para garantizar que los ID asignados a una dimensión pueden persistir en caso de hacer cargas completas nuevas, si sabe sobre cómo funcionan llaves subrogadas y como se implementan tradicionalmente en SQL Server, puedes continuar en Limitaciones de la Subrogada por Identity:
Llaves Subrogadas
En modelamiento dimensional una de las mejores prácticas establecidas por la metodología Kimball es el uso de llaves subrogadas. Las llaves subrogadas tienen varios beneficios importantes:
- Permiten el manejo de historia en dimensiones tipo 2 (que en realidad son atributos tipo 2). Básicamente da la habilidad de tener múltiples filas para la misma llave de negocio, con lo que persiste el estado de los datos a través de la historia de la entidad. Por ejemplo, si un cliente era del tipo detallista hasta el día de ayer y a partir de hoy se convirtió en mayorista; el modelo de llave subrogada permite manejar 2 filas, la primera con el atributo tipo de cliente en detallista con fecha de vencimiento de ayer y la segunda con el tipo de cliente en mayorista con fecha de inicio de hoy. Esto a su vez permite que las ventas de cada año pueden asociarse a la versión de cliente apropiada.
- Permiten que los Datamarts manejen historia que puede haber sido borrada de las fuentes originales, al mismo tiempo que permiten que se agreguen nuevas fuentes de datos que podrían tener llaves que chocan con las del sistema existente. Por ejemplo, cuando la organización compra a una empresa competidora, en el Datamart podríamos tener conflictos porque los códigos de cliente coinciden, pero en la realidad son clientes diferentes.
- Mejoran sensiblemente el desempeño de las tablas de hechos (no de la dimensión) al reducir sensiblemente ancho de dichas tablas y facilitar los JOINS con las tablas de dimensión. En general es deseable que las tablas de hechos sean altas (muchas filas) y delgadas (pocas columnas y columnas estrechas).
- Permiten agregar filas que no existen en la fuente original pero necesarias para dar contexto apropiado a los hechos. Por ejemplo, si en una tabla de hechos de ventas, tenemos fecha de despacho y el producto no ha sido despachado, podemos agregar una fila para la fecha (suelo usar números negativos: -1) para indicar que no ha sido despachada.
Más información sobre llaves subrogadas en el blog post de Surrogate Keys, de Ralph Kimball (en ingles).
Implementación en SQL Server de llaves Subrogadas
La forma tradicional de implementar llaves subrogadas en SQL Server es por medio del IDENTITY. En la gran mayoría de las implementaciones se usa esta habilidad del motor de la base de datos aunque alternativamente puede usarse un SEQUENCE. Un buen ejemplo de cómo implementar una llave en código TSQL:
CREATE TABLE Dimensions.Customers( CustomerID INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_Customers PRIMARY KEY, --- Business Key CustomerCode VARCHAR(10) NOT NULL, --- Name FirstName VARCHAR(50) NOT NULL, MiddleName VARCHAR(50) NOT NULL, LastName VARCHAR(50) NOT NULL, --- TODO: Add LOTS of attributes ---- Metadata DimStart DATETIME NOT NULL, DimEnd DATETIME NULL ); SET IDENTITY_INSERT Dimensions.Customers ON; INSERT Dimensions.Customers(CustomerID, CustomerCode, FirstName, MiddleName, LastName, DimStart, DimEnd) VALUES (-1, '****', 'Invalid Cust.', '', 'Invalid Cust.', '19000101', NULL) , (-2, 'CASH', 'Cash Cust.', '', 'Cash Cust.', '19000101', NULL) SET IDENTITY_INSERT Dimensions.Customers OFF;
En el código se puede ver como se agregan dos clientes no existentes para manejar errores de integridad (-1) o clientes de contado (-2).
Limitaciones de la Subrogada por Identity
Recientementé me enfrente a dos casos donde la implementación tradicional de llaves con número secuencial (IDENTITY) producía resultados no deseados. Estos son los dos casos:
- Cuando se tiene un Datamart que debe volver a llenar completamente, en vez de la carga incremental tradicional. Este cliente tiene una arquitectura modelo con Data Warehouse centralizado (al estilo Bill Inmon) y múltiples Datamarts (al estilo Kimball); al mismo tiempo emplea un enfoque de desarrollo ágil (Scrum). Esta combinación produce, que ocasionalmente se requieran cargas completas de los Datamarts, a sabiendas que el Data Warehouse es el responsable de preservar la historia sin perder información. Pero como los modelos dimensionales ya están en producción, estas cargas son disruptivas para los reportes y tablas pivote que referencian las llaves subrogadas. Dicho de otra forma los usuarios ya tienen tablas pivote de Excel con filtros y cuando se hace un pase a producción con carga completa, todas las referencias que el Excel se pierden ya que el ID es nuevamente autogenerado y el filtro realmente referencia a una fila diferente a la original.
- Cuando se implemento una arquitectura Lambda en un modelo de inteligencia de negocios con modelo estrella. En la arquitectura Lambda tenemos un componente que requiere procesar grandes lotes de información en lotes; y de forma paralela diseñamos un método de procesamiento de flujo que permita acceso en tiempo real a los datos. La capa de lotes, por razones históricas y desempeño, usa un modelo de estrella Kimball, y dado que una de las dimensiones degeneradas tiene un poco más de 500 millones de filas es muy útil si las cargas de hecho puedan calcular de forma independiente la llave subrogada sin necesidad de JOIN o LOOKUP de la dimensión.
En ambos casos la solución que exploramos e implementamos fue usar el HASHBYTES con MD5 sobre la llave primaria de negocio para calcular el valor de la llave subrogada.
Probabilidad de colisión al usar HASHBYTES
Para el caso donde la dimensión tenía más de 500 millones de filas, una consideración importante que debíamos analizar es la posibilidad de colisiones. Una colisión ocurre cuando dos valores diferentes generan la misma llave. En este caso necesitamos algo de matemática para ver la probabilidad de colisión (si te interesa el tema puedes ver más información sobre la forma en que se calcula en la paradoja del cumpleaños):
Para un Hash de 8 bytes (64 bits):
- Los posibles resultados del hash son 1.8*(10^19) (esto es 18 trillones).
- Si aceptamos una probabilidad de 0.1% de tener una colisión o más, podemos almacenar hasta 1.9*(10^8), poco más de 192 millones de filas.
- Si queremos “ir a la segura” y solo aceptar 0.0001% de probabilidad de tener una colisión o más, solo se podrían almacenar 6,100,000 filas.
Por otra parte, si usamos un Hash de 16 bytes (128 bits):
- Los posibles resultados de un hash de este tipo son 3.4*(10^38), esto es 340 sextillones.
- Si aceptamos una probabilidad de solo aceptar 0.0001% de colisión podemos almacenar 2.6*(10^16), unos 26 mil billones de filas.
Estos resultados pueden ser poco intuitivos, y vale la pena tomar un poco de tiempo para asimilarlos. Por ejemplo, una interpretación ligera es: en el primer caso, que el 0.1% de probabilidad se interpreta como si construimos 1,000 dimensiones de 192 Millones de filas cada una; 1 de ellas tendrá 1 o más colisiones.
Implementación
Estos cálculos nos permitieron identificar patrones que queríamos usar en diferentes implementaciones:

Caso simple
La versión más simple del caso, aplica para una cantidad de filas pequeña, con valores de colisión en rangos que son más que aceptables. Por ejemplo, para 6 Millones filas el riesgo de colisión es 0.0001%. El código es:
SELECT CAST(HASHBYTES('MD5', CONCAT(CompanyCode, '|'
, CostCenterCode, '|', AccountCode)) AS BIGINT) AS AccountId
--- Other Columns
FROM Accounts
Vale la pena notar:
- La llave es BIGINT. La llave INT reduciría mucho las opciones.
- Usamos el CONCAT para unir los valores de la llave de negocio, en este caso la llave de negocios es compuesta por tres atributos: Compañia, Centro de Costos y Cuenta;
- Usamos un carácter especial (|) como separador a sabiendas de que NO se usa en los atributos llave. Si no lo usaramos, la concatenación con facilidad se pueden generan colisiones. Por ejemplo, CostCenterCode:101 y AccountCode:10, generarían el mismo código que CostCenterCode:10 y AccountCode:110. El separador previene este comportamiento.
- Usamos la función HASHBYTES con MD5. El algoritmo MD5 tiene debilidades desde el punto de vista criptográfico, pero es una muy buena opción para generación de hash. Más información del MD5.
- El CAST toma solo los valores de los primeros 16 bytes (64 bits) del HASHBYTES.
Caso simple con detección de conflictos
En este caso, la cantidad de filas es pequeña, pero se desea mantener el tamaño del Id en INT; adicionalmente los valores de colisión están en rangos que son no son aceptables. Por todo esto construimos un costoso mecanismo de detección de conflictos que por ser un cantidad de filas reducida no es tan significativo. Por ejemplo, si para 3,000 filas, el .1% de probabilidad de una o más colisiones no es aceptable, el siguiente código puede ayudar a manejar los conflictos:
SELECT (Base.BaseId/8)*8
+ ROW_NUMBER()
OVER (PARTITION BY Base.BaseId
ORDER BY CompanyCode, CostCenterCode, AccountCode)-1 AS AccountID
FROM Accounts
CROSS APPLY (SELECT CAST(HASHBYTES('MD5', CONCAT(CompanyCode, '|'
, CostCenterCode, '|', AccountCode)) AS INT) AS BaseID
) AS Base
Vale la pena rescatar:
- Que el código usa un CROSS APPLY para simplificar los cálculos, el CROSS APPLY permite nombrar el cálculo del hash y reutilizarlo en el SELECT.
- La división por 8 y multiplicación por 8 básicamente quita 3 bits del entero. Esto incrementa el riesgo de colisión de 0.1% a 0.8%. Pero combinado con el ROW_NUMBER se permite manejar hasta 8 conflictos para cada HASH.
- Debe considerarse el impacto del desempeño en conjuntos grandes de datos, ya que el ROW_NUMBER sobre el cálculo del HASH con un ORDER BY por la llave primara, deberá hacerlo el motor relacional con un costoso SORT que probablemente impacte a la TempDB.
Caso para Dimensiones Grandes
El caso para dimensiones grandes, se puede traducir en que el BIGINT no es suficientemente grande para llevar los 32 bytes, por lo que debemos entonces usar 2 llaves BIGINT para “asegurarnos” la unicidad del valor HASH. En este caso el código base es:
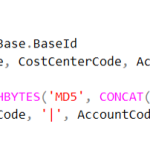
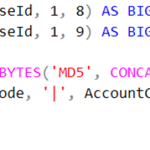
SELECT CAST(SUBSTRING(BaseId, 1, 8) AS BIGINT) AS AccountId1
, CAST(SUBSTRING(BaseId, 1, 9) AS BIGINT) AS AccountID2
FROM Accounts
CROSS APPLY (SELECT HASHBYTES('MD5', CONCAT(CompanyCode, '|'
, CostCenterCode, '|', AccountCode)) AS BaseID
) AS Base
Vale la pena resaltar:
- En este caso la llave primaria de la tabla de dimensión son 2 columnas tipo BIGINT, Esto tiene impacto en el ancho de las tablas de hechos asociadas con esta tabla de dimensión.
Conclusiones
La práctica descrita en este artículo, es lo que en el modelo Cynefin llamaría una práctica emergente, para resolver problemas que tradicionalmente no enfrentamos en inteligencia de negocios. Los resultados obtenidos con la generación de llaves subrogadas generando un hash sobre llaves de negocios produjo excelentes resultados, pero debe tomarse el tiempo el diseñador para calcular la probabilidad de colisiones y la forma que va a manejarse dicha situación.
Has enfrentado alguna vez:
- ¿La necesidad de mantener las llaves subrogadas de la dimensión, porque los usuarios tienen ya pivotes y reportes previamente generados? ¿Cómo lo resolviste?
- ¿la necesidad de cargar datos en tiempo real y agregarlos a una tabla de hechos con identificadores subrogados al estilo Kimball?
Me interesa mucho saber si alguna vez has enfrentado un problema de esta naturaleza y si vez alguna alternativa o mejora a esta práctica que deberia considerar
Deja una respuesta