
El comando DBCC SHOW STATISTICS es un comando que nos permite ver la información interna que SQL almacena para llevar control de la densidad y cardinalidad de una tabla con el objetivo de determinar la selectividad de una consulta. Si quieres aprender más sobre estos conceptos y sus definiciones puedes revisar en el posteo “Que son las estadísticas en SQL Server y para qué sirven”. La sintaxis del comando en su versión más simple pero completa es:
DBCC SHOW_STATISTICS ('Demo2', 'STA_Demo2_Col2_Col3');
El comando retorna tres secciones independientes: el encabezado, el vector de densidad y el histograma.
El encabezado de DBCC SHOW STATISTICS
El encabezado es la sección donde se almacena información general sobre las estadísticas.
![]()
La mayoría de las columnas pueden entenderse solo con ver su nombre y no requieren mayor explicación, pero con frecuencia el ojo entrenado se fija tres secciones:
- UPDATED: para evaluar si la estadística es muy vieja. Es importante señalar que una estadística vieja no necesariamente es un problema, pero es un síntoma que puede estar asociado a problemas más profundos (en inglés llamados code smell). Cuando la fecha es muy vieja, deben cuestionarse: ¿Está la opción de AUTO UPDATE STATISTICS deshabilitada?; ¿Tiene la tabla deshabilitada las estadísticas(sp_autostats)? ¿Tiene la tabla actividad o cambios? ¿Se están consultando datos sobre esta columna?
La información de la fecha de actualización también puede obtenerse de la función STATS_DATE y de la vista de catálogo sys.stats.
- NAME: si la estadística tiene empieza con nombre con: _WA_Sys_ (por ejemplo: _WA_Sys_00000008_3C69FB99) sabemos que la estadística es auto-creada. Dicho de otra forma, existe porque se hizo una consulta sobre la columna como predicado (en un WHERE o JOIN) y que no estaba indexada como primera columna. El primer número nos indica la posición de la columna en la tabla y el segundo es el object_id de la tabla en formato hexadecimal.
- ROWS SAMPLED: nos fijamos si ROWS_SAMPLED y ROWS son iguales, para entender si los datos son estimados o si el histograma está basado en todas las filas. Al igual que en el primer caso, esta información no implica un problema, pero es valiosa para determinar que el índice tiene un tamaño considerable (porque usa muestreo) y que las filas que vemos en el histograma están basadas en toda la población o en una muestra que puede ser un problema cuando los datos tienen una distribución muy irregular.
Si quiere que el SHOW STATISTICS solo despliegue información sobre el encabezado, puede hacerlo usando la opción de STAT_HEADER;
DBCC SHOW_STATISTICS ('Demo2', 'STA_Demo2_Col2_Col3') WITH STAT_HEADER;
Vector de Densidad de DBCC SHOW STATISTICS
El vector de densidad tiene el cálculo general de la densidad de la columna y es valor que se usa cuando las consultas son parametrizadas (por ejemplo: WHERE StateProvinceName=@StateProvinceName). Un ejemplo de vector de densidad:
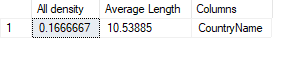
En el caso de las estadísticas con múltiples columnas se lleva control de densidad para cada columna, por ejemplo:

Entre más baja es la densidad, más selectivos son los predicados sobre esta columna y puede servir como insinuación de buenas columnas candidatas a índices.
Si desea ver la información del vector de densidad de las estadísticas, puede usar la opción:
DBCC SHOW_STATISTICS ('Demo2', 'STA_Demo2_Col2_Col3') WITH DENSITY_VECTOR;
Histograma del DBCC SHOW STATISTICS
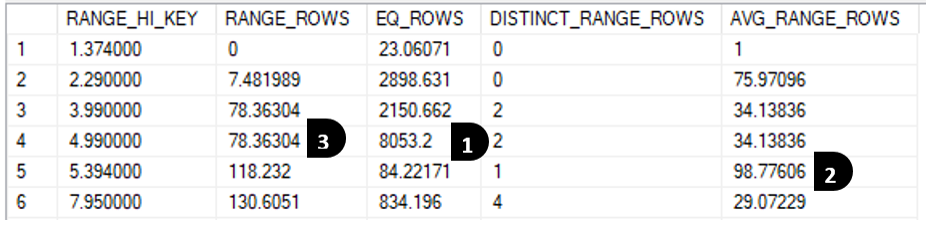
Finalmente, tenemos la sección del histograma, que es la que requiere más experiencia para leerse de forma efectiva. Esta sección es en realidad un histograma doble, uno para rangos y otro para valores. Un ejemplo de histograma:
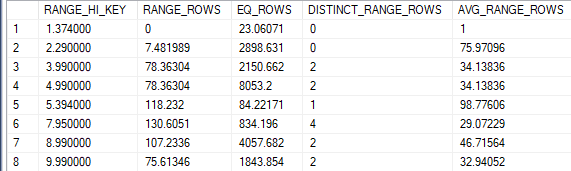
El histograma de rango, como su nombre lo indica da la cantidad estimada de filas entre el RANGE_HI_KEY y el RANGE_HI_KEY anterior, excluyendo ambos valores. Entonces si hacemos un gráfico sobre las columnas RANGE_HIGH_KEY y RANGE_ROWS sobre los primeros valores de histograma podemos visualmente entender mejor la información que captura.
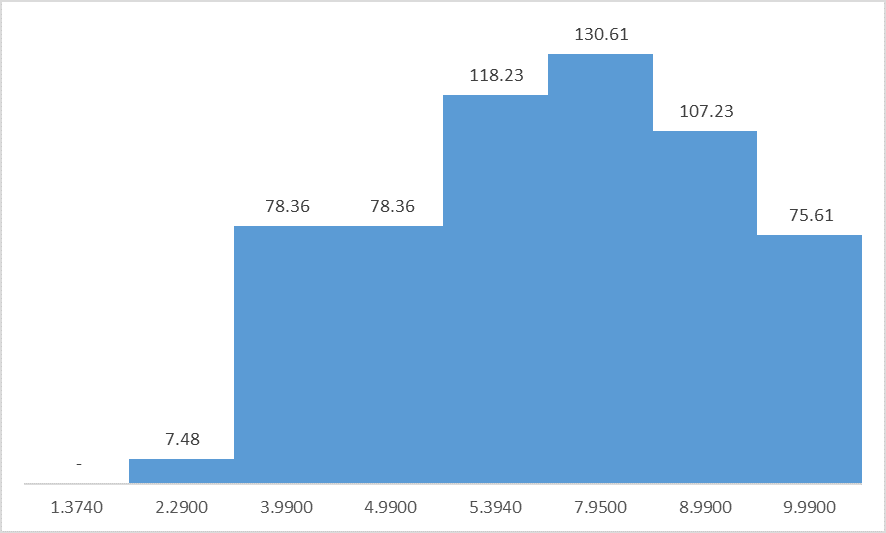
Debe notar que la cantidad de filas entre los valores excluye los limites, o sea que se estima hay 7.48 filas entre 1.374 y 2.2900 excluyendo ambos límites y que por la forma que se construye el histograma:
- el primer valor de RANGE_HI_KEY es el valor mínimo de la tabla;
- y el RANGE_ROWS de la primera fila es siempre cero, ya que no hay valores anteriores a este.
Al mismo tiempo se puede construir un histograma de los valores exactos si empleamos las columnas de RANGE_ROWS y EQ_ROWS.
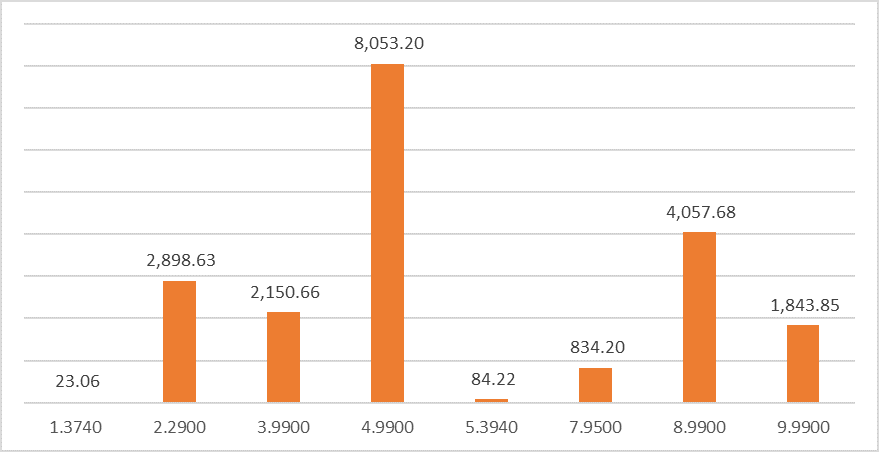
De estos gráficos se desprende que se estima hay muy pocas filas que tiene el valor 5.3940 (84.22) que son bastante menos que las que se estima tienen el valor 4.9900 (8,053.20)
Cuando se lee el histograma hay ciertos valores que sirven de guía para entender la cantidad de filas estimadas basados en los predicados.
- Si el predicado es de igualdad y el valor está en la llave RANGE_HI_KEY se usa el valor EQ_ROWS.
SELECT COUNT(*) FROM Sales.SalesOrderDetail WHERE LineTotal='4.990000' -- 8053.2000
- Si el predicado es de igualdad y el valor NO está en la llave se usa AVG_RANGE_ROWS.
SELECT COUNT(*) FROM Sales.SalesOrderDetail WHERE LineTotal='5.250000' -- 98.7761
- Los predicados de rango usan las filas de RANGE_ROWS cuando coinciden con las llaves del RANGE_HI_KEY y adicionalmente usan los EQ_ROWS si el rango cubre múltiples llaves (RANGE_HI_KEY)
SELECT COUNT(*) FROM Sales.SalesOrderDetail WHERE LineTotal>3.990000 AND LineTotal<4.990000 -- 78.3630
 Si desea que el SHOW_STATISTICS solo despliegue solo la información sobre el histograma:
Si desea que el SHOW_STATISTICS solo despliegue solo la información sobre el histograma:
DBCC SHOW_STATISTICS ('Demo2', 'STA_Demo2_Col2_Col3') WITH HISTOGRAM;
Conclusión
Saber leer los resultados del comando DBCC SHOWSTATISTICS es fundamental para los administradores y desarrolladores de base de datos que necesitan entender porque sus consultas no se desempeñan como esperaban. El captar cómo funcionan las estadísticas te permite más adelante leer y entender mejor los planes de ejecución, optimización de consultas y creación de índices. Si desean aprender de algunos conceptos y definiciones puedes revisar el posteo de “Que son las estadísticas en SQL Server y para qué sirven”. Por otra parte, si eres de los que creen que ¨Las leyes, como las salchichas, dejan de inspirar respeto en la medida en que sabemos cómo se fabrican¨, entonces el posteo de SQL SERVER Mejores prácticas: Estadísticas, puede ser más interesante.
Deja una respuesta