
Las estadísticas son uno de los elementos más importantes que ayudan al desempeño de los servidores de SQL Server y en general suelen pasar desapercibidos a las personas que se inician en Bases de Datos. Pero, ¿Qué son puntualmente estas estadísticas?. Son objetos que mantienen información sobre el contenido de las columnas de las tablas y cuya responsabilidad consiste en llevar control sobre: la selectividad, la cardinalidad y la densidad de los datos.
Las estadísticas son especialmente “oscuras” porque de forma predeterminada los servidores de SQL Server las mantienen de forma automática e indirecta. Pero este comportamiento puede cambiar y es deseable que como administradores o desarrolladores de base de datos entendamos su funcionamiento.
Conceptos Relacionados
Como parte de la definición de las estadísticas use tres conceptos que son relevantes:
- Cardinalidad: Es una medida que describe la cantidad de valores únicos que tiene una tabla en una columna. Esta definición no debe confundirse con la definición de cardinalidad en modelado de datos, que se refiere al tipo de relación que tienen dos entidades/tablas y que puede ser: uno-a-uno, uno-a-muchos y muchos-a-muchos. Si queremos entonces calcular la cardinalidad de una columna en SQL básicamente tenemos que hacer:
SELECT COUNT(DISTINCT (MiColumna)) FROM MiTabla;
- Densidad: Es una medida que se utiliza para medir la frecuencia con que ocurren valores duplicados en una columna y es un valor “opuesto” a la cardinalidad. Opuesto en el sentido que dada una cantidad de filas en una tabla una mayor cardinalidad necesariamente implica una menor densidad. Si queremos calcular la densidad en SQL entonces usaríamos:
SELECT COUNT(*)/COUNT(DISTINCT (MiColumna)) FROM MiTabla;
La interpretación de la densidad es el promedio de filas duplicadas que para cada valor tiene una columna en una tabla.
- Selectividad: Es el número de filas que satisface un predicado. Para entender esta definición deber entonces definir predicado, como una expresión que se evalúa como verdadera o falsa. En SQL calcularíamos la selectividad como:
SELECT COUNT(*) FROM MiTabla WHERE MiColumna=Valor; -- Predicado
Es importante rescatar que la selectividad estimada de una consulta, se calcula basada en los valores de cardinalidad y densidad. Por ejemplo, en el código anterior el servidor genera una estimación de la Selectividad basado en el predicado “MiColumna=Valor”. En otras ocasiones como por ejemplo cuando usamos GROUP BY o DISTINCT la cardinalidad es la estadística que nos permite estimar mejor la cantidad de filas que una consulta genera.
Finalmente, para que nos sirve toda esta teoría y definiciones: básicamente para entender cómo funciona el optimizador de consultas y para tomar decisiones sobre cuales índices vale la pena construir y cuales índices no van a ser nunca usados por el optimizador.
¿Para qué sirven las estadísticas?
Las estadísticas son la principal fuente de información para que usa el optimizador de consultas para tomar decisiones de cómo resolver una consulta. Con las estadísticas el optimizador puede estimar la selectividad de los predicados y así tomar decisiones sobre cuando usar un índice o no, o la forma en que hacen JOIN las tablas. Aparte de las estadísticas también usa la información de sys.sysindexes, funciones de partición, CHECKS y otros.
Por ejemplo, aun cuando las dos siguientes consultas tiene el mismo patrón o forma, generan planes de ejecución diferentes:
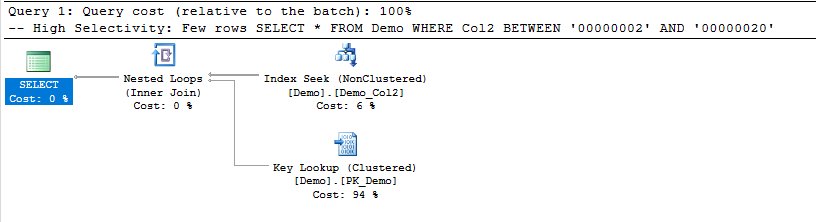
-- High Selectivity: Few rows SELECT * FROM Demo WHERE Col2 BETWEEN '00000002' AND '00000020'
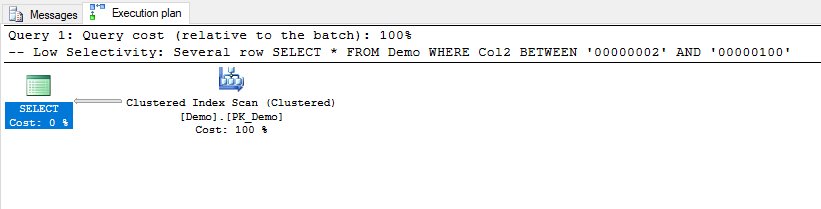
-- Low Selectivity: Several row SELECT * FROM Demo WHERE Col2 BETWEEN '00000002' AND '00000100'
En la primera consulta el optimizador de consultas utiliza un índice no agrupado (non clustered index) para filtrar las filas y luego hace un bucle anidado (nested loop) para obtener los valores de las columnas del índice agrupado (clustered index). Esto significa que en el primer diagrama usa el primer índice para filtrar y el segundo para extraer los valores de las columnas.
Por otra parte, en la segunda consulta la cantidad de filas que satisfacen en predicado (Col2 BETWEEN ‘00000002’ AND ‘00000100’) es suficiente para que no valga la pena usar el índice no agrupado y entonces el optimizador decide obtener directamente los valores del índice agrupada y filtrar.
¿De dónde se obtiene la información sobre la cantidad de filas? La estimación de filas viene de las estadísticas que el servidor de SQL Server lleva sobre la cardinalidad y la densidad de las columnas, lo que le permite cuando resuelve la consulta estimar que en el ejemplo anterior la estimación para la primera consulta era de 18.6 filas, y en la segunda de 127.3
También puedes leer sobre como leer estadísticas (DBCC SHOWSTATISTICS), y sobre SQL SERVER Mejores Prácticas: Estadísticas.
Deja una respuesta