
Un problema recurrente de muchas bases de datos de SQL Server es encontrar índices duplicados. Aun cuando no llevo una estadística formal, me atrevo a decir que en dos de cada tres casos aparece esta situación. Si el servidor y la base de datos no están muy ocupados, la situación suele pasar desapercibida y no es importante; pero cuando el servidor tiene problemas de rendimiento, suele traducirse en problemas de contención de escritura, bloqueos y deadlocks (abrazos mortales). Entonces si tienes esos síntomas, puedes buscar índices duplicados en la base de datos y decidir cuales borrar y cuales dejar. El código adjunto sirve para este propósito, puede bajarlo de GitHub de DuplicateIndexes2.sql
¿Por qué se producen los índices duplicados?
Hasta la versión de SQL Server 2017, el motor de base de datos solo construye índices de forma automática cuando creas una llave primaria o llave única. Todos los demás índices son construidos por los desarrolladores, administradores de la base de datos o en algunos casos por generadores automáticos de código si se emplean estas herramientas. En cualquiera de los casos, un problema recurrente en la industria, es optimizar consultas y no la base de datos o el servidor. Entonces con frecuencia se siguen ciegamente las recomendaciones del optimizador de consultas, y se termina con una creando un número excesivo de índices, y rara vez se analizan otras opciones de optimización como: cambiar la sintaxis de la consulta, cambiar ligeramente algún índice existente, particionar, comprimir u otras opciones de optimización. Es importante evaluar el costo del índice en las sentencias de inserción, actualización y borrado de la tabla.
Consulta para encontrar índices duplicados
Cuando empecé este artículo, creí que solo iba ser copiar y pegar la consulta que suelo usar en mi práctica profesional, pero me di cuenta que tenía dos limitaciones:
- No era fácil de leer, ya que la mayoría de la interpretación del resultado la hacía yo, no la consulta.
- Estaba desactualizada, sobre todo por la gran cantidad de cambios que los índices columnares (Columstore indexes) e índices hash en memoria (Hash inmemory) introducen.
Entonces busqué en internet, pero las versiones que encontré no me terminaron de convencer. Basado en mi versión y en los cambios introducidos les presento una nueva versión, que es una mejora significativa, pero que tiene dos limitaciones: No esta tan probada como la versión anterior y tiene bastante campo para mejoras. El código puede bajarlo de GITHUB de <>.
La consulta agrupa los resultados en 4 condiciones que van de más a menos grave.
- Índices con las mismas llaves (1 Same Keys): Son pares índices que tienen exactamente las mismas llaves, por lo que probablemente son redundantes, pero NO necesariamente son idénticos. Unos podrían ser restricciones de tabla (PRIMARY KEY o UNIQUE), podrían tener INCLUDES diferentes, compresión diferente, o incluso filtros diferentes. Aunque casi siempre puedes eliminar alguno de los dos índices o fusionarlos, debes analizar cada caso con detalle.
- Índice incluido en otro (2. Included): Son índices donde uno de ellos está incluido en el otro. Asumiendo que puedas justificar el índice con más columnas, entonces probablemente deber eliminar el que tiene menos columnas, estudiando diferencias que podrían tener (restricciones, INCLUDE, compresión, etc.). Al igual que en el caso anterior casi siempre puedes eliminar alguno de los índices o fusionarlos, pero en algunas excepciones se justifica su existencia.
- Índices con más de tres columnas iniciales compartidas. (3+ Shared Keys) En este caso, la condición es más una prevención, para valorar la efectividad de los índices y la selectividad de los mismos. En bases de datos donde se usan llaves primarias compuestas esta es una situación esperada, pero que debe ser controlada.
- Llaves compartidas (9. Shared Keys): Dependiendo del tipo de base de datos que tengas esta condición puede ser corriente o irrelevante, pero si tu base de datos fue diseñada por un fanático de IDENTITY, entonces podría a ayudarte a eliminar algunas llaves.
Si solo te interesa el resultado de la consulta puedes bajar el código y dejar de leer, ya que a continuación se dedica a desglosar paso a paso y solo sirve si quieres personalizar la consulta o si quieres aprender algunos trucos de lenguaje de SQL.
Explicación Paso a Paso
La consulta es una consulta que usa múltiples CTEs (Common Table Expressions) y usa algunos trucos para evitar el potencial uso de cursores y tablas temporales. Puedes pensar en la CTE como una “vista temporal” que vive solo durante la ejecución del comando. Las CTEs empleadas son:
- BaseNumbers es una CTE Recursiva, o sea que tiene dos secciones unidas por un UNION ALL. La primera sección (llamada Ancla) se ejecuta una vez; y la segunda parte (recursiva) se ejecuta repetidas ocasiones hasta que no retorne resultados. Entonces BaseNumbers retorna un conjunto de datos con los números del 1 al 32. 32 es máximo número de columnas que pueden participar en una llave de un índice de SQL Server. BaseNumbers podría fácilmente cambiarse por una tabla utilitaria equivalente.
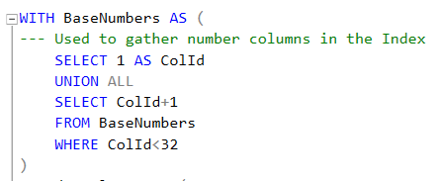
- IndexColums es donde realmente se acceden todas las tablas del sistema para obtener la información de índices de la tabla. Se puede inferir el contenido de la tabla por su nombre, pero vale la pena acotar lo siguiente:
- sys.indexes: con una fila para cada índice o heap en la base de datos. Si quiere personalizar y mejorar el código, considere las columnas is_primary_key, is_unique_constraint, has_filter y filter_definition, como opciones valiosas. Las dos primeras para darles preferencia a estos índices y no borrarlos, y las dos últimas para tomar consideraciones especiales para índices filtrados. El ojo entrenado puede observar que en la versión de SQL 2017 tiene una nueva columna auto_created que es una señal de funcionalidades futuras.
- sys.objects: con una fila para cada objeto definidos de usuario (“no de sistema”). Usada solo para obtener nombres de esquema y objeto. Alternativamente se pueden usar la función OBJECT_NAME. Uso la tabla porque interesa también poder filtrar objetos creados por Microsoft.
- sys.schemas: con una fila para cada esquema de base de datos. Alternativamente puede usar la función OBJECT_SCHEMA_NAME
- sys.index_columns: con una fila para cada columna llave en el índice o heap y que define la granularidad de la consulta.
- sys.columns: con una fila para cada columna. Empleo esta tabla para obtener el nombre de la columna. Si quiere mejorar el código considere las columnas de system_type_id y de max_length como opciones valiosas para incorporar información del ancho de índice a la consulta.
Note que la CTE IndexColumns filtra los datos para que no se incluyan los Heaps, ni objetos instalados por Microsoft; que limita los índices a Tablas y Vistas; finalmente que solo incluye índices B+, a saber índices agrupados (CLUSTERED), no agrupados (NONCLUSTERED) y no agrupado hash (NONCLUSTERED HASH). Si quieres saber mas sobre tipos de índices de SQL Server puedes leer el artículo SQL Server: Tipos de Índices en SQL Server.
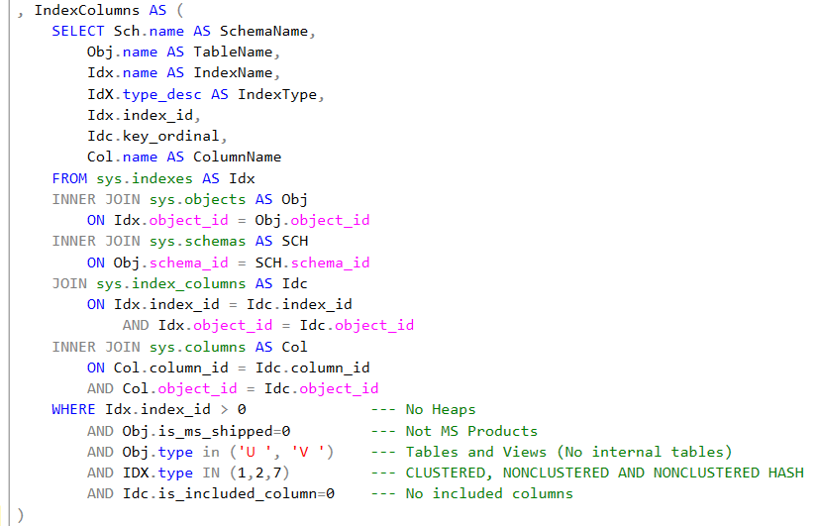
- IndexColumnsAgg es una CTE recursiva que uso para concatenar cada columna llave con las columnas anteriores. Por ejemplo, si tienes una llave definida para tres columnas como: CodigoPais, CodigoEstado, CodigoPostal.; esta consulta genera un conjunto de datos que tiene tres filas: CodigoPais, CodigoPais-CodigoEstado, CodigoPais-CodigoEstado-CodigoPostal. Esto porque solo es interesante comparar que la columna CodigoPostal que está en el tercer nivel del índice debajo de CodigoPais y CodigoEstado, con índices que tienen esta misma condición y no con otro índice que tiene CodigoPostal en el primer nivel o CodigoPostal como tercer nivel de un índice que tiene otros dos atributos en los primero niveles. Esto se logra en la línea que concatena ColumnName con el CONCAT de forma recursiva.
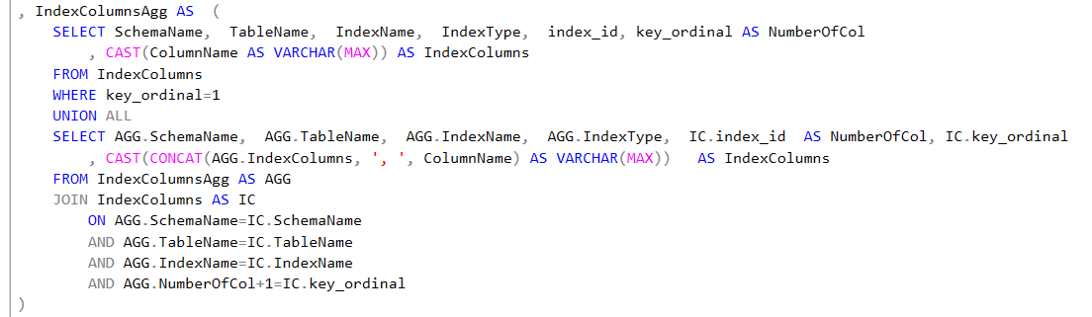
- IndexColumnsAggExt: es una CTE que emplea la función LAST_VALUE. LAST_VALUE es una función analítica de ventana que al usar el OVER permite valorar cuál es la cantidad total de columnas y cuales son todas las columnas que participan como parte de la llave del índice. Debe notar que esta CTE mantiene la granularidad, o sea una fila para cada una de las columnas que participa en el índice.
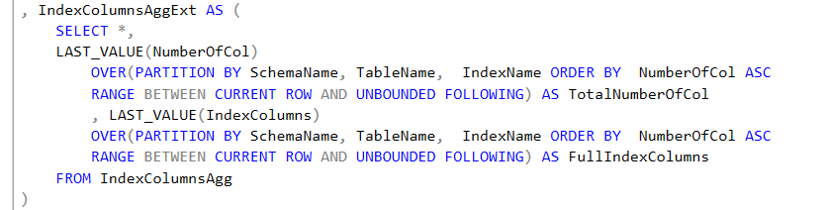
- IndexPairs: Utiliza los resultados anteriores para comparar los índices que pertenecen a la misma tabla (esquema y nombre) y que compartan las mismas columnas. Hay tres cosas que vale la pena notar sobre esta consulta.
- Usa un self join, que es una técnica que une a una tabla con ellas misma.
- Se usa una condición de menor que en L.index_id<R.index_id en lugar de su alternativa de diferente que (<>), porque así se evita que aparezca dos veces el mismo par de índices ya que A=B y B=A.
- La granularidad no es apropiada para análisis. Por ejemplo, si una tabla tiene dos índices: el índice ABCDE tiene 5 columnas (A, B, C, D y E) y el índice ABCFD tiene 5 columnas (A, B, C, F, D). Entonces comparten las tres primeras columnas ABC y el conjunto tiene 3 filas, ya que en realidad se comparan A=A, AB=AB y ABC=ABC. Note que D no se reporta.
- Para controlar el problema de granularidad se agrega una función ROW_NUMBER, que permiten numerar las coincidencias de llaves entre índices. Entonces siguiendo el ejemplo anterior ABC=ABC se le asigna 1, AB=AB un valor de 2 y A=A se le asigna 1.
- Consulta Final: Filtra los datos para reparar la granularidad al filtro WHERE Pos=1, y define una “regla de negocio” que clasifica la gravedad de acuerdo al criterio especificado anteriormente.
Como siempre te insto a bajar el código de bajarlo de GitHub (DuplicateIndexes2.sql); a que lo pruebes y lo ajustes a tus necesidades, ¡todavía mejor si me compartes los resultados!
Deja una respuesta