
Cómo una capa de ingesta aburrida se convierte en la base para ops, calidad y gobernanza — sin un proyecto de catálogo separado.
Abrís una llave y sale agua. Seis posts después, ese sigue siendo el marco correcto. Si llegás recién, empezá por Post 1 — este es el cierre de la serie. Si llegaste hasta acá: esto es lo que la infraestructura estaba generando en silencio todo el tiempo.
«We kill people based on metadata»
En abril de 2014, el ex director de la NSA y la CIA, Michael Hayden, habló en un simposio en Johns Hopkins en medio del debate legislativo post-Snowden. La NSA había estado recolectando metadatos de empresas de telecomunicaciones — registros de llamadas, no el contenido de las llamadas. Quién llamó a quién, cuándo, por cuánto tiempo, desde qué ubicación, desde qué dispositivo. Sin conversaciones grabadas. Sin contenido interceptado.
«We kill people based on metadata,» dijo Hayden.
La cita es perturbadora; ése es el punto. Hayden no estaba defendiendo la política de targeting — estaba reconociendo en qué se había convertido el sistema. Los metadatos ya no eran el subproducto del trabajo de inteligencia; eran el producto. Su propio punto: «los metadatos le dicen absolutamente todo sobre la vida de una persona.» Un patrón de llamadas — a quién contactás a qué hora, desde qué ubicación, cuánto duran esas llamadas — es suficiente para tomar decisiones de targeting sin escuchar una sola palabra.
Ahora pensá en el equipo de datos corporativo promedio.
Tienen metadatos. Clasificaciones de PII en un catálogo. Documentación de schema. Campos de data owner en una planilla. Logs de ejecución en una base de datos que nadie consulta. Los capturaron — frecuentemente a un costo significativo, un sprint o más. Pero los metadatos existen y no producen nada. Ninguna decisión depende de ellos. Ningún proceso los lee automáticamente. Son un impuesto de cumplimiento pagado al lanzamiento, sin retorno sobre la inversión después de eso.
La NSA no solo recolectó metadatos. Actuó sobre ellos — continuamente, sistemáticamente, como el output primario de un sistema diseñado para ese propósito. El punto no es la vigilancia — es la preparación para la decisión. El sistema de Hayden conecta metadatos con decisiones de targeting por diseño. La mayoría de los catálogos enterprise no conecta metadatos con ninguna decisión. La pregunta no es si capturar metadatos. Es si tu sistema actúa sobre ellos — o los deja como evidencia de gobernanza sin la sustancia de ella.
En un sistema diseñado como describimos, actuar sobre los metadatos no es un segundo proyecto. Es el output natural de una plataforma que siempre los estaba generando. Los runbooks, notebooks post-ingesta y bucles de retroalimentación YAML de los Posts 4-5 ya están actuando sobre ellos donde los bucles están cableados. Los reportes vienen después.
Este post conecta los cables que todavía están sueltos.
Los metadatos muertos son la norma
El patrón que todo profesional aplicado vivió.
Un equipo pasa un sprint en el catálogo de datos. Agregando descripciones, asignando propietarios, validando clasificaciones de PII, dibujando lineage. El día del lanzamiento, el catálogo es 95% preciso y está hermosamente organizado.
Semana tres: se incorporó una fuente nueva. La entrada del catálogo estaba en cola pero no se creó todavía — el sprint de esta semana fue todo incidentes. El schema de Sales_Salesforce.Opportunities tuvo una columna eliminada aguas arriba. El catálogo todavía la lista. El data owner asignado se movió a otra unidad de negocio. Nadie actualizó el campo.
Mes seis: el equipo de gobernanza corre una auditoría. El sesenta por ciento de las entradas del catálogo no fueron tocadas desde el lanzamiento. Nadie puede decir cuáles son precisas y cuáles están desactualizadas. El catálogo es ahora un pasivo — da la apariencia de gobernanza sin la sustancia de ella.
Tres formas de metadatos muertos, un modo de falla:
| Forma | Cuándo era precisa | Cuándo dejó de serlo |
|---|---|---|
| Diccionario de datos en Confluence | El día del lanzamiento | El sprint siguiente |
| Diagrama de lineage en una slide | El día que se dibujó | El primer cambio de schema |
| Data owner en una planilla | Cuando se asignó | Cuando cambió el organigrama |
El fallo es estructural, no de comportamiento. Los metadatos se convirtieron en un documento que alguien tenía que mantener, compitiendo con todo lo demás en el backlog. Cuando perdieron esa competencia — y siempre la pierden — silenciosamente dejaron de ser verdad mientras seguían pareciendo oficiales.
Gartner mapeó esto en su 2022 Market Guide for Active Metadata Management (G00756612, De Simoni & Beyer): cinco niveles de madurez, de Nivel 0 (Sin conciencia) al Nivel 5 (Aumentado). La mayoría de los equipos de datos enterprise están en Nivel 1 o Nivel 2 — actualizaciones programadas, descriptores coordinados, técnicamente preciso al lanzamiento.
El catálogo era preciso el día del lanzamiento.
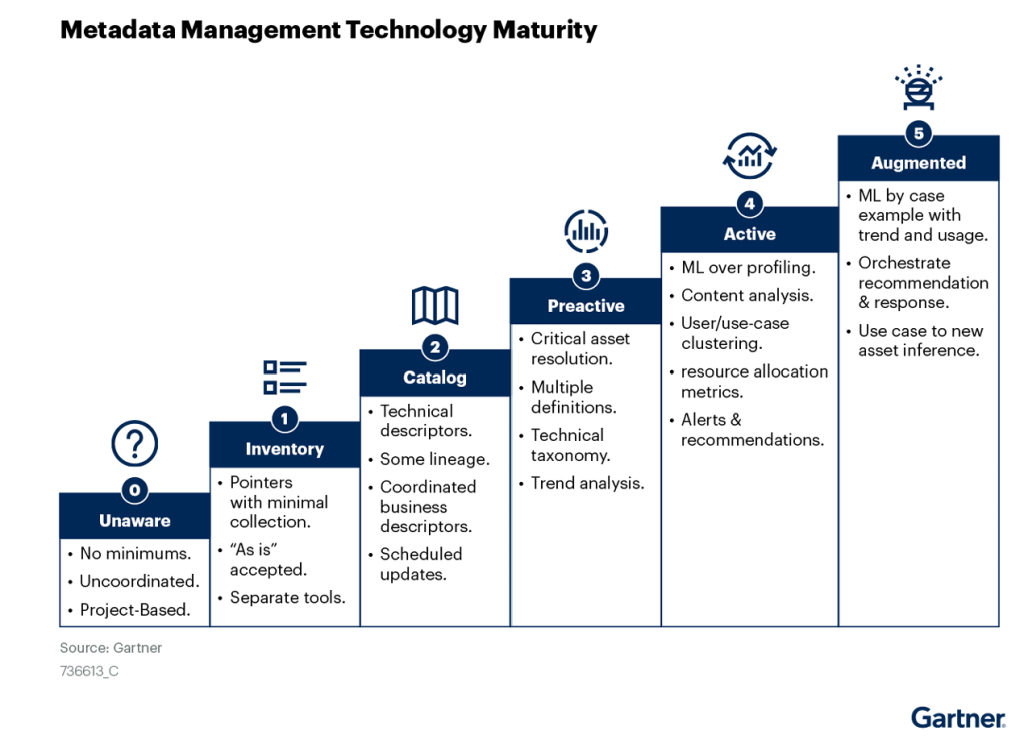
El Nivel 3 — lo que Gartner llama Preactivo — es donde los metadatos empiezan a trabajar para vos: detección de schema drift, resolución de assets críticos, análisis de tendencias. La plataforma descrita en esta serie genera esas capacidades como efecto secundario de la ejecución, no como un proyecto separado. El Nivel 4 agrega ML sobre profiling y recomendaciones automatizadas — fuera del alcance aquí, pero no fuera del alcance una vez que tenés la base.
Activo versus pasivo, en el sentido de madurez de Gartner, no es una elección de herramienta. Es una consecuencia de diseño. Un catálogo de Nivel 2 fue construido para ser mantenido por humanos; pierde contra el backlog cada vez. Un sistema de Nivel 3 genera metadatos continuamente desde la ejecución; nadie tiene que acordarse de actualizarlo.
Este sistema ya genera metadatos en vivo
Acá está el giro. Si construiste lo que describieron los Posts 1-5, tu plataforma estuvo generando metadatos con cada ejecución. No construiste un catálogo — estuviste generando uno.
El DMBOK v2 define los metadatos operativos como «logs de ejecución de jobs, historial de extracciones, lineage de creación» (Cap.12, §1.3.2.3). Cada tabla de esta plataforma coincide exactamente con esa definición:
| Tabla | Qué captura | Frecuencia |
|---|---|---|
control.PipelineLog | Estado de run, dominio, inicio/fin, error, tags | Cada ejecución de pipeline |
control.activitieslog | Actividad por entidad, path YAML, versión YAML, row counts | Cada carga de entidad |
control.VolumeCheckQuarantine | Anomalías de volumen, umbrales, estado de resolución | Cada verificación de volumen |
control.SchedulerLocks | Estado de lock, timestamps de adquisición/liberación | Cada ciclo del calendarizador |
catalog.columnas | Schema por entidad, clasificación PII, timestamp de captura | Cada captura de schema |
catalog.entidades | Registro de entidades: dominio, fuente, país, config file | Cada deployment |
catalog.config_files | Auditoría de config: hash de commit git, deployed_at | Cada deploy de YAML |
La distinción clave desde el Post 2: estos son metadatos operativos — generados por la ejecución, según la definición del DMBOK arriba. Una regla de diseño que la plataforma agrega encima: estas tablas nunca se editan a mano. El Post 2 manejó metadatos de configuración: nacidos del contrato, viven en Git. Diferente origen, mismo principio. El YAML es configuración; todo lo que estas tablas capturan es operativo.
En la mayoría de los Lakehouses, catálogo e ingesta son equipos separados, herramientas separadas, cadencias separadas. En esta plataforma, catalog.columnas se actualiza con cada ejecución de ingesta. El catálogo no es un proyecto. Es un efecto secundario.
De logs a decisiones: la capa Gold
Los ingenieros de operaciones consultan las tablas de control directamente — los runbooks del Post 5 llevan esas consultas exactamente para ese propósito. Para todos los demás — data quality stewards, comités de gobernanza, stakeholders de negocio — los logs de ejecución crudos son el punto de partida equivocado. Las decisiones necesitan un modelo semántico.
La capa de traducción es un star schema en el Gold warehouse que convierte logs en métricas, métricas en KPIs, KPIs en decisiones. Una aclaración sobre el término: cuando Medallion habla de «Gold,» generalmente se refiere a agregaciones de negocio — Ventas, Finanzas, ARR. Acá, Gold es la contraparte operativa: misma disciplina Medallion, distinto dominio. Dos capas Gold conviven en el Warehouse: una para el negocio, otra para la plataforma que lo opera.
El schema tiene tres dimensiones (Países, Fechas, Entidades) y dos hechos: Findings para anomalías de calidad y eventos de cuarentena, y QualityMetrics para scores de completitud, unicidad y validez. Una restricción dura: cero PII en Gold. La capa Gold contiene solo métricas agregadas — nunca los datos de filas subyacentes. catalog.columnas puede referenciar qué columnas tienen tag PII, pero los valores nunca salen de Bronze.
La cadena de transformación:
La cadena de transformación:
| Log crudo | → Métrica | → KPI | → Decisión |
|---|---|---|---|
control.PipelineLog | % tasa de éxito | Cumplimiento de SLA | Escalar / Aceptar |
control.VolumeCheckQuarantine | Anomalías esta semana | Score de calidad | Ajustar umbrales |
catalog.columnas | Eventos de drift por entidad | Estabilidad de schema | Priorizar revisión |
catalog.entidades | Cobertura por dominio | Score de gobernanza | Reportar al comité |
La arquitectura es deliberadamente aburrida. Stored Procedures en el Fabric Warehouse leen desde las tablas del Lakehouse, cargan incrementalmente en el star schema. Direct Lake significa que el modelo semántico nunca necesita un refresh programado — Power BI lee las tablas Delta subyacentes del Warehouse directamente desde OneLake, sin round-trips a través de SQL. En Fabric, el Warehouse ve el Lakehouse como una base de datos — un three-part name [Lakehouse].[Schema].[Tabla] es todo lo que se necesita para consultar a través del límite:
--- Carga incremental desde el Lakehouse de metadatos
--- al star schema Gold
SELECT RunID, Domain, StartTime, EndTime, Status, RowCount
FROM lh_metadatos.control.PipelineLog
WHERE LoadDateUTC > @last_loaded
Ese es el patrón para cada tabla de hechos. Sin Kafka. Sin EventHub. Sin plataforma de observabilidad dedicada. Un Stored Procedure y un parámetro delta. Y cada fila lleva su propio lineage — RunID, BatchID, SnapshotDate — sin una herramienta de lineage separada.
Un ejemplo concreto de principio a fin: Sales_Salesforce.Opportunities gana una nueva columna CloseDate_Adjusted en la fuente. Un notebook post-ingesta, una tarea opcional pero recomendada que dispara después de cada ejecución de pipeline, consulta la tabla ingestada, compara su schema actual contra el último estado registrado en catalog.columnas, y escribe cualquier columna nueva o eliminada como evento de drift. La captura de schema se declara junto con las demás tareas post-ingesta en el YAML de la entidad:
post_ingestion_tasks:
volume_check:
enabled: true
min_rows: 1000
max_rows: 5000000
schema_capture:
enabled: true
Detecta CloseDate_Adjusted y lo registra. Gold muestra: «3 eventos de schema drift esta semana en el dominio Sales.» El data quality steward abre una revisión: ¿es intencional esto? ¿La columna necesita un tag PII? El YAML se actualiza via PR. Siguiente ejecución: catalog.columnas refleja la clasificación; el dashboard de gobernanza muestra cobertura 100% restaurada.
Un evento. Una revisión. Cero actualizaciones manuales del catálogo.
Tres audiencias, una fuente
Las mismas tablas sirven a tres audiencias con preguntas muy diferentes. La mayoría de las plataformas construye una de estas — el dashboard de ops — y lo llama listo. Las tres importan, y las tres son accesibles desde la misma fuente.
Data Platform Console — Bronze Observability. La pestaña Overview muestra KPIs en vivo y enruta a tres vistas específicas por audiencia: Operations, Data Quality y Schema Evolution.
Operaciones — fuentes primarias: control.PipelineLog, control.activitieslog, control.SchedulerLocks. Las preguntas: ¿corrió? ¿Cuántas filas? ¿Qué falló? ¿Hay locks activos? La capa de decisión: alertas en Teams, disparadores de runbooks, decisiones de reintento. El equipo de ops no necesita abrir un archivo YAML para saber si las cargas de anoche se completaron.
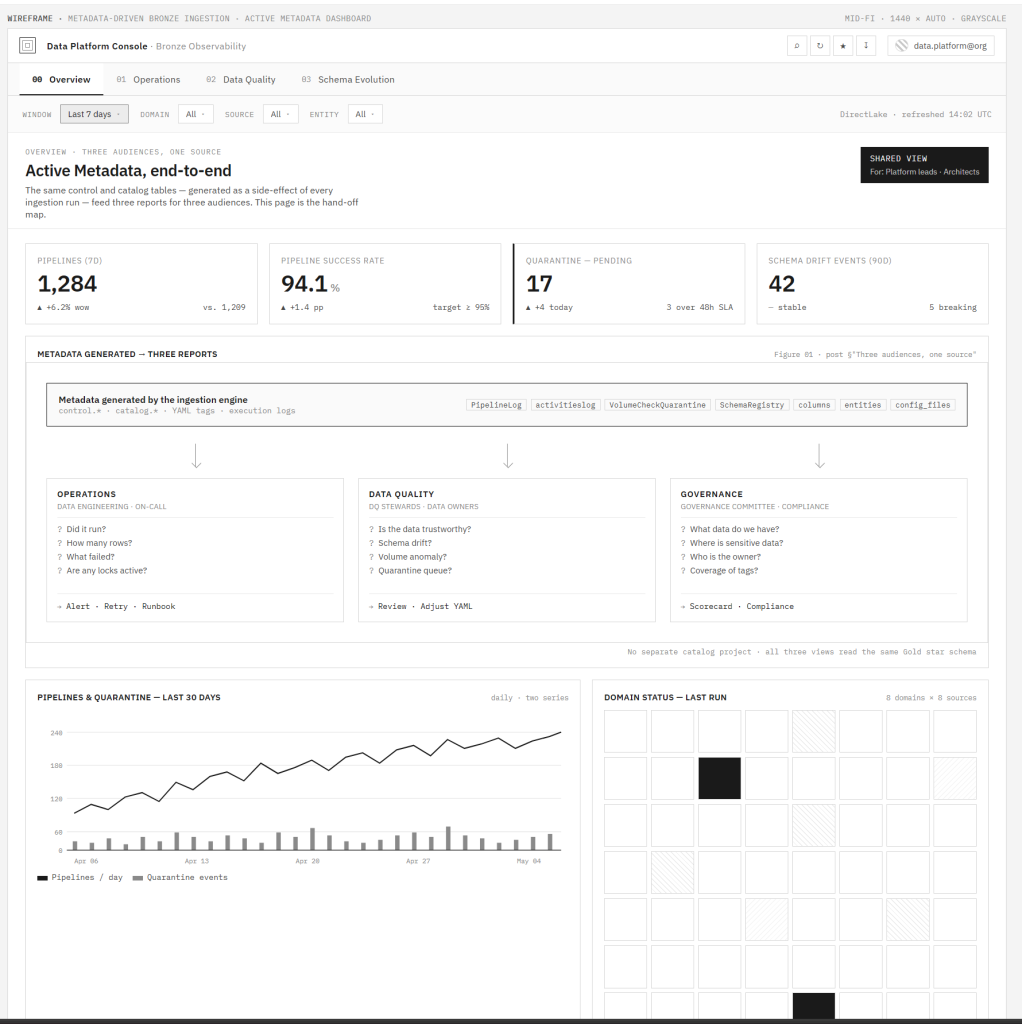
Vista de Operations: volumen de pipelines, locks activos, detección de breach de SLA y top de runs fallidos — todo desde control.PipelineLog y control.activitieslog.
Calidad de datos — fuentes primarias: control.VolumeCheckQuarantine, catalog.columnas. Las preguntas: ¿son confiables los datos? ¿Hay schema drift? ¿Está creciendo el backlog de cuarentena? El schema drift detectado en catalog.columnas es la señal temprana, antes de que alguien reporte «los números se ven raros.»
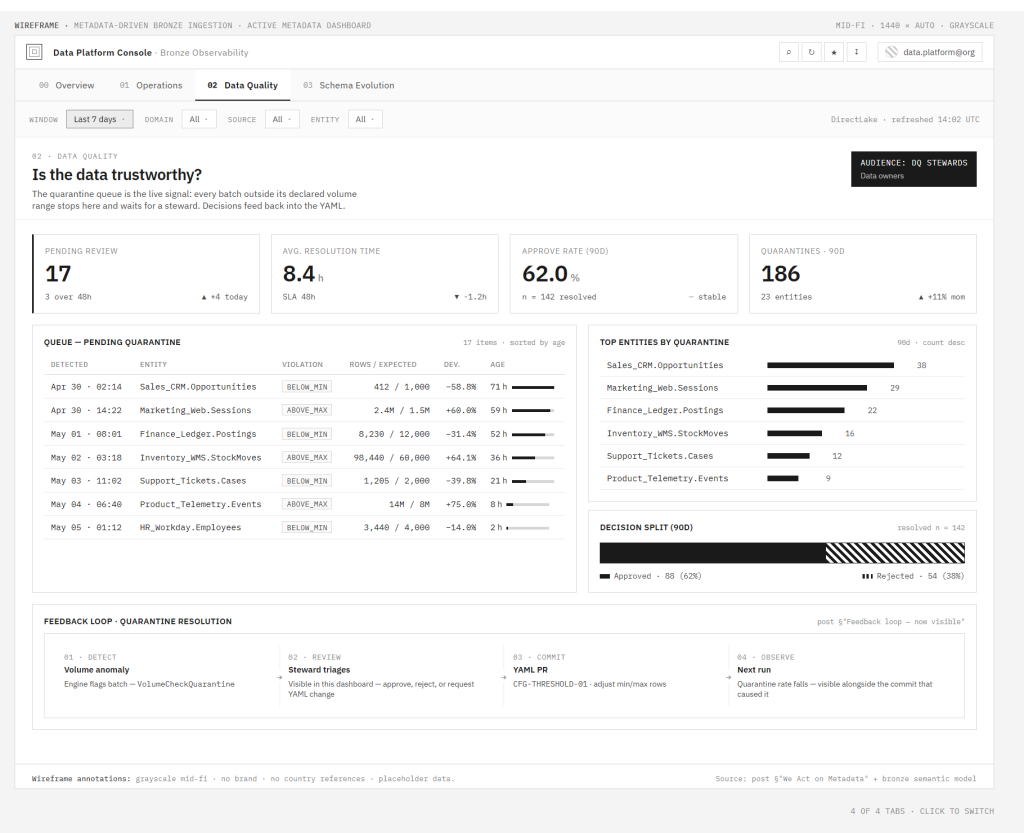
Vista de Data Quality: cola de cuarentena con volumen vs. rangos esperados, flujo de resolución, y el bucle de retroalimentación hecho visible — desde anomalía de volumen hasta ajuste de umbrales en YAML.
Gobernanza — fuentes primarias: catalog.entidades, catalog.columnas (pii_classification), catalog.config_files, más el historial Git de los propios archivos YAML — una traza de auditoría completa de cada decisión de configuración, expuesta a través de catalog.yaml_changes una vez que su ETL esté cableado (ver más abajo). Las preguntas: ¿qué datos tenemos? ¿Dónde está el PII? ¿Quién es el propietario? ¿Están clasificadas todas las columnas? El comité de gobernanza no abre Power BI — pero el analista de gobernanza que los briefea sí. El dashboard reemplaza un reporte trimestral armado manualmente con una vista en vivo sobre datos que el sistema genera continuamente.
Los tags YAML del Post 2 — security.sensitivity, governance.data_owner — están vivos aquí. Actualizados via Git PR, no en una UI de catálogo manual. La lente de gestión de cambios ya está completa: cada archivo YAML lleva su historial Git completo — un registro a prueba de manipulación de cada decisión de configuración tomada, quién la propuso, quién la aprobó, cuándo aterrizó, qué cambió. La disciplina GitOps del Post 1 viene generando esta traza desde el día uno. Lo que está pendiente es el cableado: un script ETL (git log --follow config/*.yml) la materializa como catalog.yaml_changes, consultable junto con los datos operativos. Hasta entonces, las mismas preguntas se pueden responder — solo que requieren git log y tiempo de un steward en vez de un JOIN de SQL. Las preguntas que cualquiera de los dos caminos resuelve:
- «¿Quién cambió la clasificación PII de Opportunities, y cuándo?» — independientemente de si la carga corrió ese día
- «¿Hubo cambios de YAML en la semana antes de este pico de cuarentena?» — correlacionar decisiones de configuración con outcomes operativos (una consulta cuando aterrice el ETL; un
git logmás cross-reference manual hasta entonces) - «¿Qué YAMLs no fueron tocados en 12 meses?» — detección de config obsoleta: una fuente sin commits recientes y row counts decrecientes merece una revisión
- «¿Cuántas fuentes nuevas se incorporaron este trimestre?» — velocidad de crecimiento y carga del equipo, contadas desde
change_type = 'created'
La traza de auditoría de Git ya es un activo de gobernanza. El ETL solo la vuelve consultable.
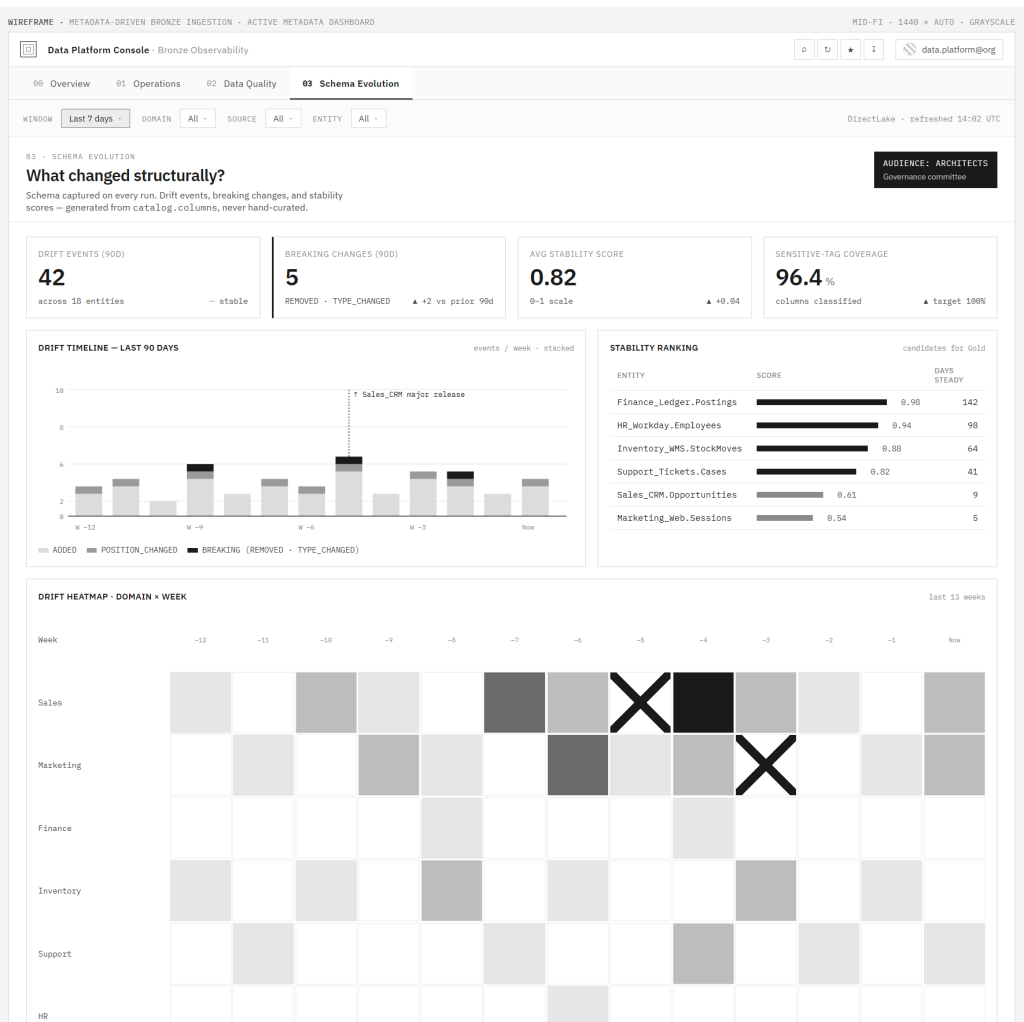
Vista de Schema Evolution: eventos de drift en 90 días, breaking changes, scores de estabilidad por entidad, cobertura de tags sensibles, y un heatmap dominio × semana — todo generado desde catalog.columnas, nunca curado a mano.
Los datos se generan automáticamente. Nadie tiene que acordarse de actualizar catalog.columnas cuando cambia un schema — la próxima ejecución de ingesta lo hace. Nadie actualiza control.VolumeCheckQuarantine manualmente — se puebla cuando se viola un umbral. El dashboard es una vista sobre estado en vivo, no sobre un documento mantenido.
El bucle de retroalimentación — ahora visible
Estos patrones de retroalimentación existían antes del Post 6. El schema drift disparó actualizaciones de YAML en el Post 4. Las anomalías de volumen empujaron ajustes de umbral. Las columnas nuevas dispararon tags PII. El bucle siempre estuvo ahí. Lo que agrega el Post 6 es visibilidad — el bucle ahora es consultable desde el mismo dashboard que los datos operativos a los que responde. Antes: podías trazarlo via git blame si sabías qué buscar. Ahora: podés verlo en Power BI junto con los eventos que lo dispararon.
Los patrones del bucle — ahora consultables:
- Schema drift →
catalog.columnascaptura la columna nueva → data quality steward revisa → YAML actualizado viaCFG-SCHEMA-01 - Anomalía de volumen → la entidad va a cuarentena → YAML
min_rows/max_rowsajustado viaCFG-THRESHOLD-01 - PII en columna nueva →
catalog.columnaslo detecta →security.classification: "PII"agregado via PR - Correlación de cambio de config → Git ya registra el ajuste de umbral;
catalog.yaml_changes(una vez cableado) te permite unirlo con la tasa de cuarentena que siguió en una sola consulta SQL
En la mayoría de los Lakehouses, el bucle de retroalimentación es una reunión. En este sistema, es un commit — observable, comparable con diff, rastreable al evento que lo disparó.
Los trade-offs honestos
Este sistema te da mucho. Vale la pena ser explícito sobre lo que no te da.
Metadatos de negocio. Lo que Sales_Opportunities.CloseDate significa para un analista de negocio — su definición de negocio, sus reglas de cálculo, cómo se relaciona con el ARR — todavía requiere input humano. Ninguna cantidad de captura de schema llena esa brecha. Tenés metadatos técnicos y operativos. Los metadatos de negocio siguen siendo un proyecto de documentación.
Lineage enterprise. Tenés lineage Bronze: cada fila se traza a su sistema fuente, run y batch. No tenés lo que le pasa a los datos después de que salen de tu Lakehouse. Si Opportunities alimenta un ERP downstream o un reporte financiero, ese lineage vive fuera de tus tablas de control.
Alertas completamente cableadas. RunbookRef como dimensión de primera clase en analytics de ops — mencionado en el Post 5 — es aspiracional. El cableado entre el payload de alerta y el ID de runbook todavía no es automático. Los analytics están; la plomería para hacer que las alertas se auto-identifiquen todavía requiere trabajo de tooling.
Dos piezas todavía no cableadas. El Warehouse, los Stored Procedures y el modelo semántico están construidos y en vivo. Los dashboards están diseñados y en construcción — «los datos están listos» es verdad, «los dashboards están en vivo» todavía no. catalog.yaml_changes es la segunda pieza: la traza de auditoría de Git está completa, solo está pendiente el ETL que la materializa como tabla consultable. Hasta que aterricen las dos: los dashboards viven en mockups, y las correlaciones config-vs-outcome requieren git log más cross-reference manual de un steward.
El config drift sigue siendo una disciplina manual. catalog.config_files ayuda a detectarlo — podés comparar el hash del commit desplegado contra el HEAD actual de Git. Pero no hay CD automatizado. Cada deploy requiere que un humano copie el YAML al Lakehouse y corra un smoke test. CFG-SYNC-01 documenta el procedimiento; el procedimiento todavía depende de que el ingeniero se acuerde de seguirlo. La detección mejoró; la prevención no.
Lo que sí obtenés: observabilidad sin un stack de observabilidad separado. Cobertura de gobernanza sin un proyecto de catálogo separado. Monitoreo de calidad sin una herramienta DQ separada. Estos emergieron como efectos secundarios de diseñar bien la capa de ingesta desde el día uno. No los agregaste — los descubriste.
La llave, revisitada
Acá está el sistema completo, dicho sin rodeos.
Un motor fijo de componentes especializados maneja fuentes relacionales y de archivo — los mismos patrones se extienden a REST APIs — sin código nuevo por fuente. N archivos YAML declaran qué ingestar, cómo clasificarlo, quién es el propietario, qué gobernanza aplica. Yamale valida la forma de cada YAML antes de que se deploya. El nombre del archivo codifica el dominio como un contrato político, no solo una convención de nombres. Cada cambio a cada YAML pasa por Git — revisado, comparable con diff, reversible.
El calendarizador declara la frescura de datos como un contrato. Los locks distribuidos previenen la doble ejecución. La política de reintentos vive en un solo lugar. Cada decisión de programación es un commit de Git.
Las cicatrices de producción están codificadas donde corresponden — en el YAML, no en conocimiento tribal. El motor maneja formatos de fecha legacy, cargas parciales, locks zombie y desfases de config sin intervención humana. Donde no puede, un runbook mantiene el procedimiento. Versionado. Delimitado. Listo para las 3am.
Y todo eso — cada ejecución, cada cambio de schema, cada anomalía de volumen, cada lock adquirido y liberado — estuvo generando metadatos todo el tiempo. Seis posts para construir el motor. Este post para cablear lo que el motor siempre estuvo produciendo.
El Post 1 abrió con una llave. Bronze debería ser aburrido. La infraestructura es invisible. Abrís la llave y sale agua — no pensás en los caños.
El Post 6 cierra con lo que pasa cuando la llave funciona: dejás de pensar en la llave y empezás a pensar en qué hacés con el agua.
La plataforma dirigida por metadatos no solo ingesta datos de forma más confiable. Genera el material crudo para decisiones de operaciones, calidad y gobernanza como efecto secundario natural de estar bien diseñada. No construiste un catálogo. No levantaste una plataforma de observabilidad. No comisionaste un proyecto de reportes de gobernanza. Construiste una capa de ingesta que no pudo evitar documentarse a sí misma, monitorearse a sí misma, y generar el material crudo para los reportes que van a sostener decisiones sobre sí misma. Los runbooks, notebooks y PRs de Git siempre estuvieron actuando sobre los metadatos. Los dashboards son la última milla.
Bronze fue aburrido. Ese siempre fue el plan. Lo que no era obvio el día uno: la infraestructura aburrida genera metadatos interesantes. Los dashboards completan lo que el motor empezó.
Anterior: Runbooks como Infraestructura
Este es el sexto y último post de la serie «Ingesta dirigida por metadatos en YAML.» Los patrones descritos aquí provienen de varias implementaciones enterprise de Lakehouse y son independientes de la plataforma, aunque nuestra referencia es Microsoft Fabric.
Deja una respuesta