
La prueba de las 3am, y por qué la instrucción para un humano es ingeniería, no documentación.
Abrís una llave y sale agua. Los primeros cuatro posts de esta serie construyeron la infraestructura detrás de esa llave; éste es sobre lo que pasa cuando la llave se rompe a las 3:00 am y un humano tiene que responder a la alerta. Los posts 1 a 4 quedan enlazados cuando aparecen. La tesis de este post: cada cicatriz deja dos artefactos — un campo de YAML o estrategia de partición para el motor, y un runbook para el humano. El Post 4 terminó en el primero. Este post es sobre el segundo.
La infraestructura es excelente. El YAML está versionado. Las cicatrices están documentadas. Y a las 3:14am, el calendarizador dispara una alerta. control.SchedulerLocks muestra Sales_Salesforce bloqueado, adquirido hace cuatro horas, sin timestamp de liberación. El ingeniero de guardia no construyó este sistema, no escribió el YAML, y a esta hora no recuerda nada sobre la semántica de los locks del calendarizador. Lo que tiene es un celular, una conexión VPN, y un ID de runbook impreso junto a la alerta: OPS-LOCK-01.
Ese ID es infraestructura o teatro. La diferencia lo es todo.
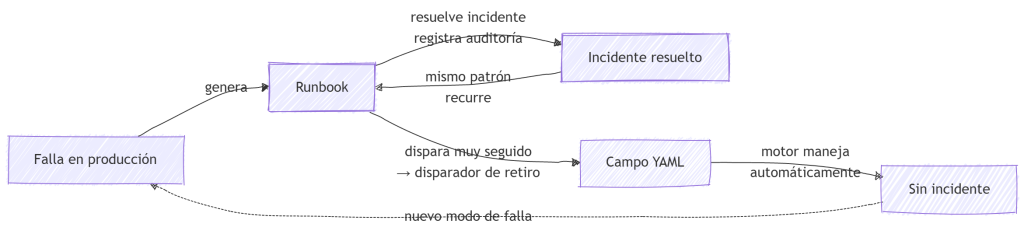
La relación entre cicatrices y runbooks es la arquitectura, no un efecto colateral. Cada cicatriz es una lección que el motor no anticipó. El campo de YAML codifica la solución para que el motor la maneje la próxima vez. El runbook codifica lo que hace el operador en la ventana entre «el motor chocó contra una pared» y «el motor fue actualizado para manejar esto» — una ventana que puede ser minutos o años, según si absorber el patrón en el YAML vale la inversión de ingeniería. Algunos runbooks se quedan para siempre, porque el modo de falla requiere juicio que ninguna configuración puede codificar. Muchos se retiran en el YAML y el conocimiento se convierte en contrato — el conocimiento operativo acumulado de la organización, construido en producción por personas que lo aprendieron a las malas.
Por qué la mayoría de los runbooks ya están muertos
La mayoría de los equipos de ingeniería de datos tienen algo que llaman runbook. Una página de Confluence. Una carpeta en SharePoint. Un hilo fijado en Teams. Un documento en el OneDrive de alguien con el nombre «Notas de Operaciones (v3 final)». La forma varía. El modo de falla no.
Todos se separan del sistema en ejecución. El YAML evoluciona. La tabla de control se renombra. Una nueva estrategia de partición cambia la lógica de reintentos. El runbook sigue describiendo la versión vieja, en silencio, sin ninguna prueba que detecte la divergencia.
Llamémoslo teatro de documentación. Produce los artefactos que una auditoría espera ver. Llena una columna en una lista de cumplimiento. Parece preparación operativa. Y en el momento en que ocurre el incidente real, el runbook no coincide con el sistema, y el ingeniero vuelve a la única estrategia confiable — adivinar y llamar a alguien.
Cuatro síntomas de un runbook podrido:
- Nombres incorrectos por todos lados. Nombres de tablas, columnas, rutas — el schema cambió y nadie actualizó el runbook.
- Pasos que ya no son pasos. «Corré el script nocturno» — el script nocturno fue reemplazado por un pipeline hace seis meses.
- Modos de falla ausentes. El runbook se escribió antes de que existiera
parquet_date_fix. No hay entrada paraINCONSISTENT_BEHAVIOR_CROSS_VERSION. El ingeniero está solo. - Silencioso sobre prevención. El runbook asume que ya sabés que hay un problema. Te dice qué hacer cuando dispara una alerta — pero no qué revisar antes de que dispare. El monitoreo proactivo — qué dashboards revisar al inicio del turno, cómo se ve la frecuencia normal de ejecución del calendarizador, qué señales tempranas preceden a un evento de throttling — nunca se escribe, porque nunca es lo que está en llamas hoy.
El resultado: tus runbooks son buenos para la recuperación y mudos sobre la prevención. La biblioteca solo se activa después de que algo ya falló.
La prueba de las 3am
Una prueba. Todo lo demás se desprende de ella.
Dale el runbook a un ingeniero que no construyó el sistema. Despertalo a las 3am. Dale la alerta y el ID del runbook. ¿Puede ejecutarlo sin llamarte?
Si no: el runbook no está terminado. No importa qué tan bien escrito esté, cuántos diagramas tenga, cuántos revisores lo aprobaron. Si ejecutarlo requiere contexto que no está en la página, el runbook es una ayuda de memoria, no un runbook.
Cuatro sub-pruebas que exponen fallas:
- La prueba de ejecución: ¿puede el ingeniero ejecutar la celda de SQL en el lugar contra el lakehouse adjunto, o tiene que traducir parámetros de memoria antes de que funcione?
- La prueba del «qué sigue»: después de cada acción, ¿está claro qué verificar antes de pasar al siguiente paso?
- La prueba de escalación: si la acción #3 no lo resuelve, ¿hay una persona nombrada a quien contactar, y el runbook tiene su información de contacto?
- La prueba del runbook-equivocado: ¿puede el ingeniero determinar en 30 segundos si éste es el runbook correcto para su situación? ¿O eso requiere leer tres secciones primero?
La cuarta sub-prueba es donde la mayoría de los runbooks fallan silenciosamente. Dispara la alerta. El ingeniero encuentra un runbook que parece relevante. Ejecuta el paso 1. Luego el 2. En el paso 3 se da cuenta de que su situación es sutilmente diferente a la que el runbook fue escrito — y ya tomó una acción que era correcta en el escenario equivocado.
La forma más reconocible de esta falla: el sistema se rompe a las 3am, el ingeniero de guardia no puede resolverlo, y todos esperan hasta las 8am para que llegue el desarrollador original. El runbook existe. Al SLA no le importa.
La tentación del que escribe runbooks: asumir que el lector tiene contexto. No lo tiene. Tiene adrenalina y un celular. No asumás ninguno de los dos.
Anatomía de un runbook — siete secciones, siempre
Todos los runbooks tienen las mismas siete secciones, en el mismo orden. La consistencia importa porque el ingeniero de las 3am está escaneando, no leyendo.
# OPS-LOCK-01 -- Scheduler Lock Not Released
## Scope limits
This runbook covers one scenario: a stale scheduler lock where the load is confirmed NOT running. If the load IS running (active RunID in control.NotebookLog), STOP -- do not release. If the release does
not unblock the scheduler within 10 minutes, see OPS-RETRY-01.
This runbook does NOT diagnose why the lock was never released.
For recurring patterns (3+ in 7 days), see GOV-POST-MORTEM-01.
## Symptom
- Alert: SchedulerLocks shows IsLocked=true, LockAcquiredTime more
than 2x the longest expected run duration.
- Downstream effect: load has not fired on its expected cadence.
- Typical page: "OPS-LOCK-01: Sales_Salesforce stuck for 4h 12m"
## Diagnosis
Run this query to confirm the lock is stale:
SELECT LoadKey, IsLocked, LockAcquiredTime, LockReleasedTime,
TIMESTAMPDIFF(MINUTE, LockAcquiredTime, current_timestamp())
AS age_minutes
FROM control.SchedulerLocks
WHERE LoadKey = '<LoadKey from alert>';
If LockReleasedTime is NULL and age_minutes > 120, proceed to Action.
If age_minutes is under 120, the load may still be running -- STOP,
check control.NotebookLog for an active RunID before releasing.
## Action
Release the lock with an explicit reason:
UPDATE control.SchedulerLocks
SET IsLocked = false,
LockReleasedTime = current_timestamp(),
ReleasedReason = 'OPS-LOCK-01: stale lock, RunID <X> failed at <ts>'
WHERE LoadKey = '<LoadKey>' AND IsLocked = true;
Replace <X> with the failed RunID from control.NotebookLog.
## Audit trail
- ReleasedReason must reference OPS-LOCK-01 explicitly (grep-able later).
- Open an incident ticket and link this execution.
- If this is the 3rd OPS-LOCK-01 in 7 days for the same LoadKey, escalate.
## Escalation
- Primary: @oncall-data (Teams channel #data-oncall)
- Secondary: @platform-lead (Teams DM)
- If OPS-LOCK-01 repeats (3+ in 7 days), open a post-mortem.
## Rollback
Not applicable. Releasing a stale lock has no undo -- the scheduler will re-acquire a new lock normally on the next cycle. If the load fires after release and produces unexpected row counts, see OPS-VALIDATE-01.
Siete secciones, por qué este orden:
Scope limits es la sección más subestimada del conjunto. Le dice al ingeniero dónde termina este runbook. Sin ella, el ingeniero estira el runbook a escenarios para los que no fue diseñado — y toma acciones que eran correctas en una situación diferente. Scope limits te permite salir en 30 segundos sin ejecutar un solo paso. Cada sección que sigue asume que te quedaste.
Symptom, Diagnosis, Action hacen el trabajo obvio: confirmar el escenario, prevenir que ejecutes la acción en el escenario equivocado, y dar SQL parametrizado que corre en el lugar contra el lakehouse adjunto.
Audit trail es lo que separa un desbloqueo de una intervención no registrada. Seis meses después, cuando alguien consulta el historial de locks, el motivo está ahí en texto claro — no en la memoria de alguien.
Escalation le permite al ingeniero transferir sin culpa. Una persona nombrada, un canal, una condición. No «preguntale al equipo» — eso no es escalación, es un encogimiento de hombros por escrito.
Rollback cierra el ciclo: ¿se puede deshacer esto? Para operaciones de purga y cambios destructivos de schema, la respuesta honesta es no, y el runbook lo dice explícitamente. «No aplica — los datos eliminados no se pueden recuperar» es la oración más importante que puede contener un runbook sobre eliminación de datos. Escribirla obliga al autor a confrontar la irreversibilidad antes de tomar la acción, no después.
Todos los runbooks. Siempre. Sin saltarse «Audit trail» porque «es obvio». A las 3am nada es obvio.
OPS-LOCK-01 referencia otros tres IDs de runbook: OPS-RETRY-01 (cuando liberar el lock no desbloquea la carga y se necesita un reintento), GOV-POST-MORTEM-01 (cuando el mismo lock recurre suficientes veces como para justificar investigación de patrón en lugar de otra respuesta a incidente — GOV en vez de OPS porque el resultado es un artefacto formal de gobernanza, no una acción operativa), y OPS-VALIDATE-01 (cuando necesitás evaluar el estado de una recuperación antes de declararla completa). Ninguno se muestra aquí — ése es el punto. Los runbooks en una biblioteca forman una red de referencias cruzadas, no una lista plana. Cada uno es acotado; la red cubre el espacio completo de escenarios. OPS-LOCK-01 te dice todo lo que necesitás para liberar un lock atascado. No intenta ser todo lo demás.
Tres tipos de runbooks, una disciplina
No todos los runbooks toman el mismo tipo de acción. Tres tipos, misma anatomía de siete secciones.
Runbooks ejecutables. Celdas de SQL, shell o Python que el ingeniero corre en el lugar. OPS-LOCK-01 es ejecutable: en el 95% de los casos la acción correcta es idéntica. Son la mayoría y los que más vale la pena escribir primero.
Runbooks narrativos. Ricos en juicio. Árboles de decisión. CFG-DATE-FIX-01 — decidir si extender parquet_date_fix a una columna nueva — es narrativo: tres preguntas diagnósticas secuenciales, cada una con ramas, porque una respuesta incorrecta puede corromper silenciosamente datos aguas abajo. La estructura fuerza el juicio en vez de ocultarlo.
Runbooks diagnósticos. Solo lectura. Sin sección de Action. El objetivo no es arreglar nada — es producir una evaluación estructurada que enrute al ingeniero al runbook correcto. OPS-VALIDATE-01, por ejemplo, se ve así:
# OPS-VALIDATE-01 -- Assess State of a Failed Run
## Scope limits
Read-only. This runbook makes no changes. Use it to determine
which recovery runbook applies before taking any action.
## Procedure
1. Retrieve the RunID from control.NotebookLog for the failed window.
2. Check: did the ingestion notebook complete? (status = Failed or Partial?)
3. Check: are there orphaned locks in SchedulerLocks for this RunID?
4. Check: did post-ingestion tasks fire? (volume check, schema capture, publish)
5. Map results to the decision table below.
## Decision table
| Ingestion | Lock present | Post-ingestion | → Use |
|------------|-------------|----------------|--------------|
| Failed | Yes | Not fired | OPS-LOCK-01, then OPS-RETRY-01 |
| Partial | No | Not fired | OPS-RETRY-01 (partial path) |
| Success | No | Failed | OPS-POST-TASK-01 |
| Success | No | Success | No recovery -- investigate upstream |
## Rollback
Not applicable. This runbook performs no changes.
Su resultado es una decisión de enrutamiento, no una solución — la capa de triage que previene el error más caro de las 3am: correr el runbook correcto para el escenario equivocado. Los runbooks diagnósticos son la categoría más subdesarrollada en la mayoría de las bibliotecas, y los más valiosos antes de comprometerte con cualquier acción.
La anatomía de siete secciones aplica a los tres tipos. La diferencia está en la distribución de peso: los ejecutables tienen Action pesada; los narrativos tienen Diagnosis pesado con ramas; los diagnósticos tienen Diagnosis pesado y tabla de decisión sin Action. La misma estructura, diferente centro de masa.
Dónde viven los runbooks
En esta arquitectura, los runbooks viven dentro del mismo workspace de Fabric que el motor — no en un repo hermano, no en Confluence, no en SharePoint. Cada runbook es en sí mismo un notebook: celdas markdown para las siete secciones, celdas de código para el SQL, típicamente adjunto al mismo lakehouse lh_metadata que lee el motor. El runbook no describe las tablas de control — las consulta. Si ésta es la elección correcta para tu plataforma depende de cómo esté estructurado tu workspace; el argumento a favor son las dos propiedades que siguen.
Versionados en Git. Cada cambio de runbook es un commit. Revisado por PR, comparable con diff, rastreable con blame. Un PR que cambia la lógica de desbloqueo en el motor puede actualizar el runbook en el mismo commit. El revisor detecta el desfase en el momento de revisión, no a las 3am. El YAML y su runbook evolucionan juntos porque viven en la misma disciplina de PR.
Vivos y cerca de la operación. El runbook vive donde el ingeniero ya está. Cuando dispara OPS-LOCK-01, el ingeniero de guardia abre el notebook OPS-LOCK-01 en el mismo workspace — no otra pestaña, otra herramienta, otro login. La celda de Diagnosis corre contra control.SchedulerLocks. La celda de Action libera el lock. El SQL que realmente funcionó ya está en la celda que corrió — hacé commit. Sin «lo documento después». Después nunca llega.
Gobernanza por diseño
El límite CFG vs OPS.
En una biblioteca de runbooks de producción, una distinción resulta ser estructural: runbooks de configuración versus runbooks operativos. La diferencia no es qué hacen — es el modelo de gobernanza que llevan.
Los runbooks CFG documentan cambios proactivos al estado declarado del sistema: ediciones de YAML, cambios de schema, entradas del calendarizador. Cambios que decidís hacer antes de que algo se rompa. Como son proactivos, llevan todo el stack de gobernanza: un PR que puede revisarse y aprobarse, un diff que muestra exactamente qué cambió y por qué, un git revert que lo deshace limpiamente si algo sale mal. Alguien firmó antes de que el cambio aterrizara.
Los runbooks OPS documentan operaciones reactivas sobre instancias en ejecución: reintentar una carga fallida, liberar un lock, reprocesar una partición. Acciones que tomás porque algo ya salió mal. Como son reactivos, su modelo de gobernanza es diferente — no aprobación antes de la acción, sino registro después. ReleasedReason requerido. Ticket de incidente vinculado. Audit trail obligatorio. El runbook no pide permiso; no hay tiempo para eso a las 3am. Requiere evidencia.
El límite importa porque la categoría equivocada produce el instinto equivocado. Un ingeniero que ve una falla de ingesta y edita el YAML directamente está aplicando gobernanza CFG a un problema OPS — la solución puede funcionar una vez y crear drift de configuración que nadie conecta con el incidente de la semana pasada porque el cambio nunca pasó por revisión. La estructura de categorías mantiene ese instinto en jaque: un cambio de YAML pasa por un runbook CFG, lo que significa un PR, lo que significa un revisor.
En una biblioteca madura, los runbooks OPS frecuentemente cierran con: «Si este patrón recurre, abrir un runbook CFG para abordar la causa raíz.» El runbook OPS registra la acción de hoy. El runbook CFG previene el incidente de mañana.
El prefijo como metadato operativo.
El prefijo del ID de runbook no es una convención de archivo. Es metadato que lleva señal de gobernanza antes de que leas una sola palabra del runbook.
CFG- y OPS- llevan los modelos de gobernanza definidos arriba — stack completo y basado en registro respectivamente. Los que realmente cambian tu exposición al riesgo son los tres que la mayoría de las bibliotecas declaran y nunca llegan a escribir:
SEC- marca operaciones de seguridad: otorgamiento de acceso, rotación de service principals, revocación de permisos. Dos cosas lo distinguen de OPS. Las acciones frecuentemente tienen exposición regulatoria y pueden ser parcial o completamente irreversibles. Y a diferencia de OPS — donde registrás después de actuar — SEC requiere un aprobador nombrado en la ruta de escalación. Un runbook SEC sin uno no es una omisión de gobernanza; es un prerequisito faltante. Lo descubrís durante el incidente, no antes.
DQ- marca operaciones de calidad de datos: evaluaciones de validación, decisiones de cuarentena, corridas de profiling que alimentan el registro de gobernanza. Los runbooks DQ tienen dos audiencias: el ingeniero de guardia que los ejecuta y el data steward que revisa el informe de calidad semanal. El audit trail que producen sobrevive al incidente que los disparó.
GOV- marca evidencia formal de cumplimiento: runbooks que existen para documentar procedimientos para auditorías externas, revisiones regulatorias o certificaciones. El riesgo de un runbook GOV faltante no es operativo — aparece cuando un auditor pide evidencia y el equipo descubre que tiene una entrada en el índice pero no el runbook detrás de ella.
El índice, estructurado por prefijo, es un mapa de cobertura. Una entrada que dice «SEC-REVOKE-01 — Revocar cuenta de servicio comprometida: no documentado aún» es más que una página faltante — es una brecha de gobernanza nombrada. El dominio de seguridad tiene operaciones conocidas sin procedimiento definido. Eso es más útil que una biblioteca que no reconoce la brecha. El riesgo es visible; alguien es dueño de la decisión de no escribirlo todavía.
Éste es el mismo principio que hizo que Sales_Salesforce.yml fuera más que una convención de nombres en el Post 1: un contrato de gobernanza comprimido en un string. El prefijo del ID de runbook hace el mismo trabajo para la biblioteca de operaciones — codifica el dominio de gobernanza, el modelo de propiedad y el perfil de riesgo antes de que abras el archivo. Esa estructura es estructural: determina qué modelo de gobernanza aplica en el momento en que un ingeniero abre el runbook, no después de haberlo leído.
El ángulo LLM — el payoff de 2026.
Los runbooks como notebooks, versionados en Git, viviendo en el workspace, se convierten en algo más que documentación para operadores. Un modelo con acceso de recuperación al corpus conoce el SQL exacto, la ruta de escalación exacta, los scope limits exactos para cada modo de falla conocido en esta plataforma. No es consejo genérico de SRE. Es guía específica y ground-truth para este motor.
Cuando el ingeniero de guardia le pregunta a un LLM «¿qué es OPS-LOCK-01?», el modelo extrae el runbook actual del workspace — no un snapshot de entrenamiento de hace seis meses. La misma disciplina de Git que mantiene el runbook correcto para humanos lo mantiene correcto para el modelo. Después de resolver un incidente, el modelo puede proponer un PR que agrega el nuevo paso de diagnóstico al runbook. El humano revisa y mergea. El conocimiento se acumula.
Cuándo se retiran los runbooks — y cuándo deberían haber existido antes
Los runbooks y el motor están en conversación. Cuando un runbook dispara con demasiada frecuencia, su patrón debería migrar al YAML. Cuando el motor cambia, el runbook evoluciona en el mismo PR.
Antes de que existiera parquet_date_fix, existía OPS-LEGACY-DATES-01. Síntoma: la carga falla con INCONSISTENT_BEHAVIOR_CROSS_VERSION.READ_ANCIENT_DATETIME. Diagnóstico: encontrar la columna ofensora desde el stack trace. Acción: SQL manual para nulificar filas anteriores a 1900, volver a correr, verificar. Funcionaba. Pasaba la prueba de las 3am.
También disparó tres veces en un trimestre, en tres fuentes diferentes, cada una con columnas ligeramente distintas. Cada incidente dejaba el mismo patrón: el motor no sabía que esta fuente tenía fechas placeholder; un humano lo re-enseñaba cada vez.
Ése es el disparador de retiro. Un runbook que dispara con esta frecuencia no es un problema de documentación — es una brecha del motor. El YAML creció un bloque parquet_date_fix. El SQL manual se convirtió en configuración declarativa. OPS-LEGACY-DATES-01 fue archivado con un puntero: «Retirado: este escenario ahora se maneja declarativamente.» Lo que lo reemplazó — CFG-DATE-FIX-01 — es más estrecho: no «cómo arreglar esta emergencia» sino «cómo decidir si extender el fix declarativo existente». El alcance se redujo porque el motor se volvió más inteligente.
Los runbooks no son documentación. Son funcionalidades del motor pendientes. Cada runbook que dispara es evidencia de que el motor todavía no aprendió ese modo de falla. El objetivo no es más runbooks — es el conjunto correcto de runbooks, cada uno disparando a una tasa que justifica no absorberlo en el contrato.
La brecha que encuentra el post-mortem.
El problema inverso es más difícil. Un runbook que debería haber existido antes de que el sistema fuera a producción, y no existió.
Así es como aparece. Una plataforma de producción tiene tres runbooks de capacidad: uno para monitorear el consumo, uno para diagnosticar saturación, uno para escalar el tier de compute. En papel, la cadena parece completa. En la práctica, tiene una brecha que nadie notó durante el diseño. Escalar requiere aprobación — presupuesto, proceso, una llamada. A las 3am, cuando el consumo está al máximo y las aprobaciones están pendientes, necesitás un cuarto runbook: ¿qué hacés mientras esperás? ¿Qué cargas podés pausar sin perder SLAs? ¿Qué entidades pueden diferirse a la siguiente ventana? ¿Cómo drenás el backlog una vez que se restaura la capacidad?
Ese runbook estaba en el índice pero nunca se escribió. El ingeniero a las 3am improvisa — tomando decisiones sobre qué cargas pausar que no son suyas para tomar, sin documentar nada porque no hay nada contra qué documentar. El próximo ingeniero improvisa diferente.
La cadena de detección a mitigación tiene una brecha justo antes de la decisión que requiere autoridad. Nadie escribe el runbook puente porque escribirlo requeriría decidir quién tiene la autoridad para despriorizar qué cargas — una pregunta política que el equipo postergó. La brecha del runbook es un proxy de la brecha de decisión. Cerrarla requiere ambas.
El problema del día uno.
Incluso cuando existen todos los runbooks operativos, hay un modo de falla para el que nadie escribe: un ingeniero nuevo que necesita provisionar un entorno desde cero. Los runbooks para operaciones individuales existen. La secuencia de onboarding — qué workspace crear primero, qué identidad configurar antes de que la primera ingesta pueda correr, qué runbook CFG aplica antes de que cualquier runbook OPS sea relevante — no está en ningún lado.
En una plataforma, el runbook de seguridad requerido como prerequisito para todo acceso de ingesta había sido declarado en el índice pero nunca escrito. El ingeniero no podía avanzar sin llamar a quien construyó el sistema.
Una biblioteca de runbooks que solo opera correctamente cuando su autor está disponible no es infraestructura. Es documentación con una dependencia.
Los dos contratos
Los primeros cuatro posts construyeron el contrato con el motor. El YAML le dice al motor qué hacer. Yamale valida que el YAML esté bien formado. El calendarizador le dice al motor cuándo. La estrategia de partición le dice al motor cómo recuperarse. Todo eso es sobre hacer que la máquina se comporte.
Este post es sobre el contrato con el operador. A las 3am, cuando la máquina hizo todo lo que pudo y aún necesita un humano, la única pregunta es si ese humano tiene la instrucción que necesita, en el lugar donde la necesita, con el contexto que necesita.
Las cicatrices del Post 4 produjeron ambos contratos simultáneamente. parquet_date_fix en el YAML absorbió lo que el motor ahora puede manejar sin intervención humana. OPS-LOCK-01, CFG-DATE-FIX-01, OPS-IDEMPOTENCY-01, CFG-SYNC-01 sostienen lo que todavía requiere un humano — y esperan el día en que puedan retirarse también. Las cicatrices no son solo historia. Son estructurales. Cada campo en cada YAML que resuelve un problema de compatibilidad, cada ID de runbook que mapea una alerta a un procedimiento — esas son lecciones que el sistema aprendió en producción, codificadas en artefactos que sobreviven al equipo que las aprendió.
Esa es la naturaleza dual de un runbook: simultáneamente el producto de una falla pasada y la infraestructura de prevención para la próxima — y lo que retirás en el YAML cuando el motor finalmente aprendió la lección.
«Runbooks como infraestructura» suena burocrático. Lo que significa en la práctica: tratá lo que mantiene el sistema corriendo a las 3am con el mismo rigor de ingeniería que aplicás al código que corre durante el día. Ponelo en el workspace con todo lo demás. Versionalo. Revisalo. Delimitalo explícitamente. Conectalo a la alerta que le llega al ingeniero. Dejá que el LLM lo lea como ground truth. Y cuando el mismo runbook dispare con demasiada frecuencia, dejá de pulir el runbook — arreglá el motor.
El mejor resultado para un runbook es eventualmente no necesitarlo.
Cada cicatriz que generó un runbook es evidencia de que el sistema está aprendiendo. Cada runbook que se retira en el YAML es evidencia de que aprendió.
Qué sigue
Post 6 — Actuamos sobre los metadatos: Cada ejecución de runbook de arriba generó datos. Esas tablas de control alertaron ingenieros y resolvieron incidentes. Tienen una segunda vida: dashboards, informes de calidad, scorecards de gobernanza. Una fuente, tres audiencias.
← Anterior: Cicatrices de Producción | → Siguiente: Actuamos sobre los Medatatos
Éste es el quinto post de la serie «Ingesta de datos dirigida por metadatos en YAML.» Los patrones descritos provienen de varias implementaciones enterprise de Lakehouse y son independientes de la plataforma, aunque nuestra referencia es Microsoft Fabric.
Deja una respuesta