
Para continuar con el tema del artículo de “Diseño Dimensional: Como crear una tabla de Dimensión”, quiero revisar los elementos que normalmente uso y espero de las tablas de hechos, específicamente que consideraciones de diseño deben tomarse en una tabla de hechos modelo dimensional al estilo Kimball:
Fundamentos de Tablas de Hechos
Un único hecho
La tabla de hechos debe capturar información de un único hecho de negocios NO de varios. Este para mí es un elemento fundamental del diseño dimensional. Kimball así lo declara cuando establece en “The Data Warehouse ETL Toolkit”:
“Un registro de tabla de hechos único corresponde a un evento de medición específico”.
Cuando nos alejamos de este fundamento, hacemos que los Datamarts sean más complejos de entender por parte de los usuarios, reduciendo la usabilidad de los modelos analíticos. Al mismo tiempo si capturamos varios hechos en la misma tabla, suele tener efectos en el manejo de nulos y en la granularidad de las tablas. Esto significa que, bajo este principio, en un datamart de una empresa comercial que desea capturar información del proceso de ventas o facturación completo deben existir tablas de hechos separadas para: Órdenes de Compra Recibidas, Facturas, Albaranes (Despachos, Remitos o sustentos de entrega) en vez de tener una tabla de hechos que capture todos los eventos simultáneamente, como por ejemplo lo hace AdventureWorks.
Estándar de Nombres
Las tablas de hechos deben usar un estándar de nombres fuerte y orientado al usuario. A diferencia de objetos tradicionales estos objetos van a ser expuestos directamente a los usuarios y es fundamental que los nombres sean intuitivos. El usar nombres conceptuales también facilita el facilita el desarrollo de la plataforma analítica. Para nombres lógicos (Tablas, Vistas, etc.) suelo usar el estándar ISO 11179-5. Puedes ver más detalles en el artículo de “Diseño Dimensional: Como crear una tabla de Dimensión”.
Secciones de tabla de hechos
La tabla de hechos típica tiene dos secciones fundamentales y una opcional pero recomendada:
Medidas del Hecho (Fundamental)
Las medidas del hecho son los valores numéricos que sirve para representar el valor de negocio del hecho. Por ejemplo, uno puede valorar o juzgar una venta por la cantidad de artículos vendidos, el monto neto, el monto bruto de venta o por el costo de los artículos vendidos. Cada uno de estos conceptos son una medida del evento de negocios.
Las medidas suelen tener las siguientes características:
- Un tipo de dato apropiado a la medida que se va a capturar, pero debe tomarse en cuenta que los tipos de datos más pequeños pueden llevar a herramientas de desarrollo a confusión cuando se agregan valores, por lo que tengo una fuerte preferencia a usar los tipos de dato INT y el NUMERIC(18,4). El tipo de dato INT para los tipos enteros (positivos o negativos) aun cuando un SMALLINT podría hacer el trabajo. Por otra parte el NUMERIC(18,4) es mi preferido para montos, ya que aunque el espacio que consume un NUMERIC(19,4) es igual que el NUMERIC(18,4), pero este último esta soportado por el índice columnstore.
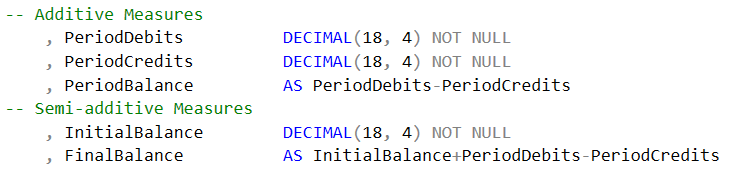
- La tabla de hechos debe tener columnas aditivas o semi-aditivas y debe prescindir de las no-aditivas.
- Las medidas aditivas son las que podemos agregar o sumar bajo cualquier contexto. Ejemplos de medidas aditivas en un datamart de Nómina, son las medidas de salarios pagados, la cantidad de ausencias o duración de las incapacidades. Las medidas aditivas suelen estar asociadas con hechos tipo flujo (que se miden durante intervalos) y con frecuencia están asociadas a documentos (acciones de personal, cheques o comprobantes de pago, etc.).
- Las medidas semi-aditivas solo se agregan en ciertos contextos o dimensiones. Más puntualmente, las medidas semi-aditivas suelen perder la habilidad de agregarse en el tiempo y se usan con variables asociadas a existencias o balances (que se miden en momentos específicos). Algunos ejemplos de medidas semi-aditivas son la cantidad de empleados, el valor del inventario o los saldos contables. Estas son medidas que podemos agregar, excepto a través del tiempo, ya que es claro que puedo agregar la cantidad de empleados de varias sucursales, pero no puedo reportar la cantidad de empleados del trimestre como la suma de los empleados de cada mes.
- En general deben evitarse almacenar las medidas no-aditivas. Estas son las que NO pueden agregarse, como por ejemplo precio o porcentaje de impuesto. Lo que si es conveniente es almacenar en las tablas de hechos los valores base necesarios para calcular estas medidas no-aditivas y dejar que las plataformas analíticas (Modelos Tabulares, Dimensionales o herramientas analíticas) realicen el cálculo usando las medidas base. Por ejemplo, en lugar de almacenar el porcentaje de impuesto se puede almacenar la cantidad y el monto para obtener la tasa de impuesto promedio con una simple división.
- Es deseable que las medidas no permitan nulos, pero en ocasiones calificadas puede tolerarse. Yo suelo cuestionarme el diseño y asegurarme de que la necesidad de nulos no sea producto de almacenar múltiples eventos de negocio o de hacer una generalización excesiva; pero hay circunstancias en que es requerido manejar nulos en las medidas.
Hay excepciones a la regla de tener las medidas de las tablas de hechos: la tabla de hechos sin medidas (en inglés: Factless Fact Table). Este tipo de tabla de hechos captura que un evento ocurrió, pero no tiene ninguna medida, lo único relevante es que el hecho ocurrió. Y la todavía más oscura, la tabla de no hechos que es la tabla de hechos que captura los hechos no ocurridos; pero estos dos son temas de otros artículos futuros.
Referencias a Dimensiones (Fundamental)
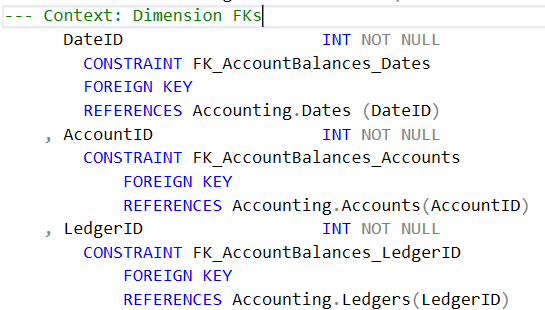
La tabla de hechos no solo captura las medidas del evento, la tabla debe capturar también el contexto en que ocurren los hechos. Este contexto lo determinan las dimensiones, por eso es que la tabla de hechos debe tener las columnas que enlacen la tabla de hechos con las tablas de dimensión y estas columnas cuentan con las siguientes características:
- Las columnas deben tener el mismo tipo que la columna que referencia. Esto significa que casi siempre deben ser de tipo INT.
- No deben permitir nulos. En caso de no conocer el valor del atributo de la dimensión, es mejor agregar una fila adicional a la tabla de dimensión que describa que ese valor es desconocido. Si el valor de la llave en la fuente rompe reglas referenciales, debe agregarse un fila adicional en la dimensión que maneje todos los errores, o alternativamente generar una fila para cada llave no encontrada como se hace con la técnica de dimensiones que llegan tarde (late arriving dimensions) .
- La relación debe estar formalizada con una llave foránea y dicha llave debe ser habilitada.
- De preferencia tener el mismo nombre que la columna que referencia, excepto para la dimensión de fechas o cuando hay una dimensión de rol (rol playing dimension), en cuyo caso debe nombrarse con rol apropiado.
En contra de la opinión popular la llave primaria NO siempre es la llave compuesta de todas las llaves foráneas. Este pensamiento esta enraizado en un tipo de inteligencia de negocios obsoleto que agregaba los datos en tablas de agregación. La tabla de hechos NO es una tabla agregada, debe tener una fila para cada hecho de negocios.
Metadata (Opcional)
El prefijo meta en epistemología se usa como acerca de sí mismo. Por ejemplo, meta-programación es la capacidad de escribir programas que manipulan otros lenguajes de programación; meta-memoria es el conocimiento o memoria que tenemos sobre los procesos de memoria; y por ende metadata es la información (o datos) que proveen información sobre datos. La metadata es un elemento fundamental de cualquier esquema de inteligencia de negocios y tanto Kimball como Inmon hacen muchas referencias a la metadata, tanto que merece su propio artículo.
Por mi parte en la tabla de hechos frecuentemente tengo una sección de metadata que captura la siguiente información:
- Metadata de ejecución: Una columna que capture información sobre el proceso que insertó la fila en la tabla de hechos. Generalmente una columna tipo UNIQUEIDENTIFIER que almacena un numero único de ejecución de la instancia del paquete SQL Server Integration Services (SSIS) que ingreso la fila. Con este valor se pueden usar JOINS con tablas de ejecuciones de paquetes y que capturan información sobre la fecha y hora de ejecución, el nombre del paquete, la versión, etc. Esta información de proceso es de gran ayuda para la solución de problemas. Un ejemplo de esta columna es:

- Llave primaria del hecho generador: Esto, cuando es apropiado, nos permite conocer cuál es la llave origen en la fuente de datos que capturo la información y la da trazabilidad a los hechos o sea permite asociar el producto final con la fuente y evaluar si las transformaciones realizadas son adecuadas. No siempre es necesario capturar este atributo, por ejemplo, puede ser que una tabla de hechos de saldos o balances contables la llave primaria del hecho generador sea la cuenta, la fecha y el libro contable. En este caso todos estos atributos están capturados en dimensiones independientes y están representados por el identificador de la dimensión. Si se captura la llave del hecho generador, entonces con frecuencia se convierte en una dimensión degenerada.
Índices y Compresión de los hechos
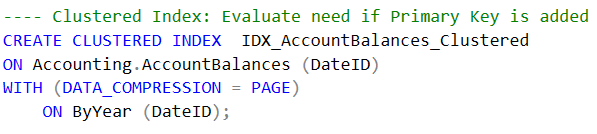
Si al Datamart no van a conectarse herramientas que hacen consultas ad-hoc, o sea si el Datamart solo es repositorio para una plataforma multidimensional, tabular u otra herramienta analítica que extrae el conjunto de completo de datos, entonces es una buena práctica que las tablas de hechos tengan un índice agrupado (clustered) sobre la columna fecha y que este índice use compresión de datos a nivel de fila. Este esquema facilita y acelera los procesos de carga y en tablas grandes permiten el particionamiento y uso del comando SWITCH y TRUNCATE WITH PARTITION (en SQL 2016+) para permitir cargas masivas que minimizan el impacto en la bitácora de transacciones. Por ejemplo, el siguiente índice ordena, comprime y particiona la tabla de hechos usando la columna fecha:
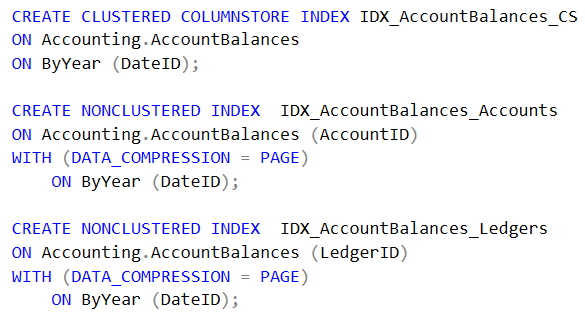
Si por el contrario el Datamart va a ser usado para hacer consultas ad-hoc debe considerarse hacer un índice columnar agrupado (clustered columnstore index) y agregar índices no agrupados a de las columnas llaves foráneas más interesantes. Por ejemplo, el siguiente índice crea un índice columnar particionado por fecha e indices alineados sobre las llaves foráneas:
Conclusiones
Espero que estos patrones de construcción de las tablas de hechos te sirvan de guía y te ayuden a construir modelos analíticos de forma más efectiva, puedes bajar el código de ejemplo de Github de los archivos DIM-003 FactTableSample.sql y DIM-003 FactTableSample2.sql.
Deja una respuesta